
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 선형회귀
- 지정헌혈
- mnist
- 크롤링
- pytorch
- 모델
- 자연어처리
- 42경산
- map
- 파이썬
- filtering
- 앱개발
- 머신러닝
- 피플
- 선형대수학
- 플러터
- Computer Vision
- 42서울
- 회귀
- 인공지능
- 데이터분석
- RNN
- CV
- 코딩애플
- Regression
- Flutter
- 딥러닝
- 크롤러
- AI
- 유데미
- Today
- Total
David의 개발 이야기!
[기계학습 입문] 타이타닉 생존자 예측 모델 Baseline 구축하기 본문
고전중에 고전 타이타닉 생존자 예측 문제를 풀어보고자 한다.
https://www.kaggle.com/competitions/titanic
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
[문제 요약]
- 1912년 타이타닉호가 빙산에 충돌하여 침몰
- 2224명의 승객과 승무원 중 1502명 사망
- 이 때 특정한 사람이 가지는 특징이 생존 여부를 결정하는 요인으로 작용함 -> ex) 어린이와 노약자가 생존율 높았음 등
1. 타이타닉 데이터 분석하기
데이터는 https://www.kaggle.com/competitions/titanic/data 에서 가져올 수 있다.
- 데이터의 속성(property)으로는 다음과 같은 것들이 존재한다.
- PassengerId: 탑승자 고유 번호
- Survival: 생존 여부 (생존: 1, 사망 0)
- Pclass: 객실 등급(1: 1등급, 2: 2등급, 3: 3등급)
- Name: 이름
- Sex: 성별
- Age: 나이
- Sibsp: 함께 탑승한 형제자매 혹은 배우자의 수
- Parch: 함께 탑승한 부모 혹은 자식의 수
- Ticket: 티켓 번호
- Fare: 티켓 요금
- Cabin: 객실 번호
- Embarked: 탑승장(Cherbourg, Queenstown, Southampton)
import pandas as pd
train_dataset = pd.read_csv("titanic_train.csv")
test_dataset = pd.read_csv("titanic_test.csv")
train_dataset.head(3)
test_dataset.head(3)
train_dataset.info()
test_dataset.info()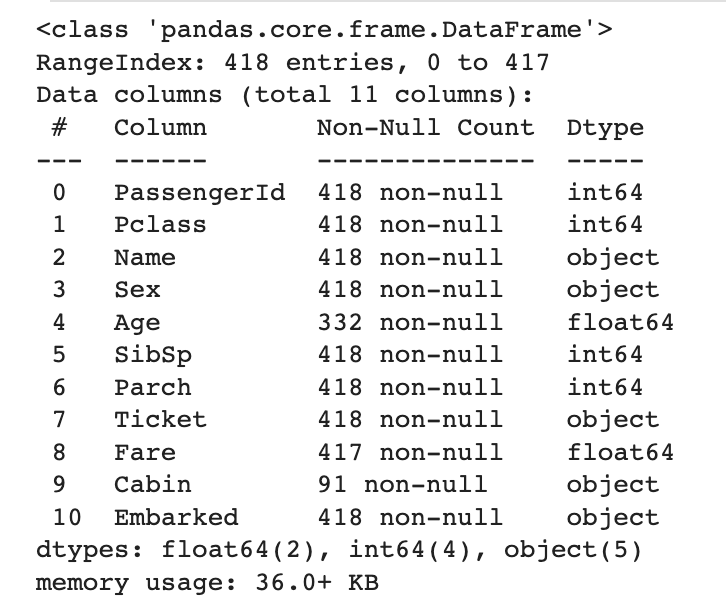
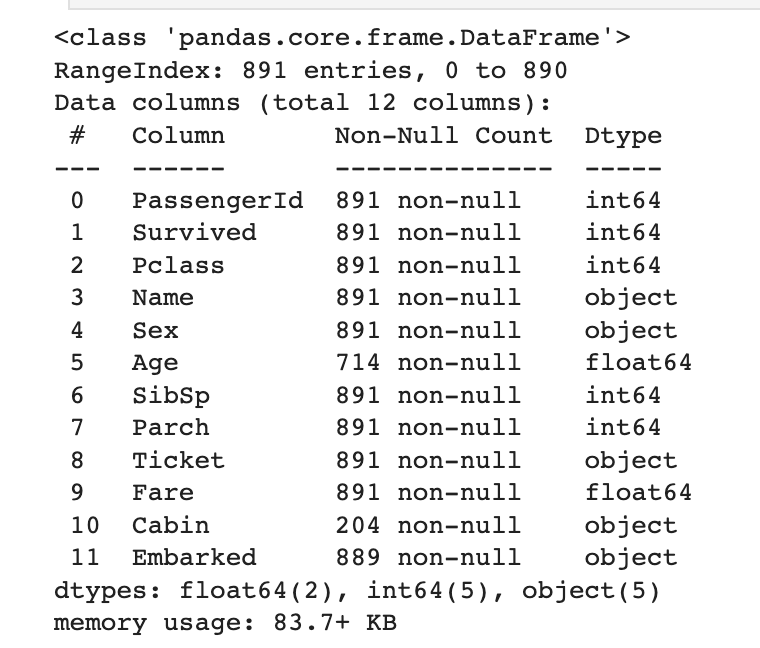
- info() 메서드를 이용하여 데이터를 전체적으로 이해할 수 있다.
- 열(column)의 개수
- 열(column)의 데이터 타입
- 존재하지 않는 데이터(NULL)의 개수
- 데이터의 크기(메모리 크기)
=> 위 데이터에서는 나이(Age)와 호실정보 (Cabin) 에 대한 정보가 많이 유실되어있음을 확인할 수 있음
통계적으로 아래와 같은 정보도 알아낼 수 있다.
#생존자 중 성별 인원
survived = train_dataset[train_dataset["Survived"] == 1]["Sex"].value_counts()
print(survived)
#사망자 중 성별 인원
survived = train_dataset[train_dataset["Survived"] == 0]["Sex"].value_counts()
print(survived)
#전체 인원 성별 인원
survived = train_dataset["Sex"].value_counts()
print(survived)
#생존/사망자 인원
survived = train_dataset["Survived"].value_counts()
print(survived)
생존자 통계를 살펴보기 위해 아래 함수를 작성할 수 있다.
def show(feature):
# 특징(feature)에 따른 생존자(survived) 수를 나타내는 컬럼
survived = train_dataset[train_dataset["Survived"] == 1][feature].value_counts()
# 특징(feature)에 따른 사망자(dead) 수를 나타내는 컬럼
dead = train_dataset[train_dataset["Survived"] == 0][feature].value_counts()
# 두 컬럼을 묶어서 데이터프레임(dataframe)으로 생성
df = pd.DataFrame([survived, dead])
df.index = ["Survived", "Dead"]
print(df)
df.plot(kind="bar", stacked=True)위 함수에 feature를 넣어주면 그거에 따른 생존/사망비율이 나옴
1. 성별 생존비율
show("Sex")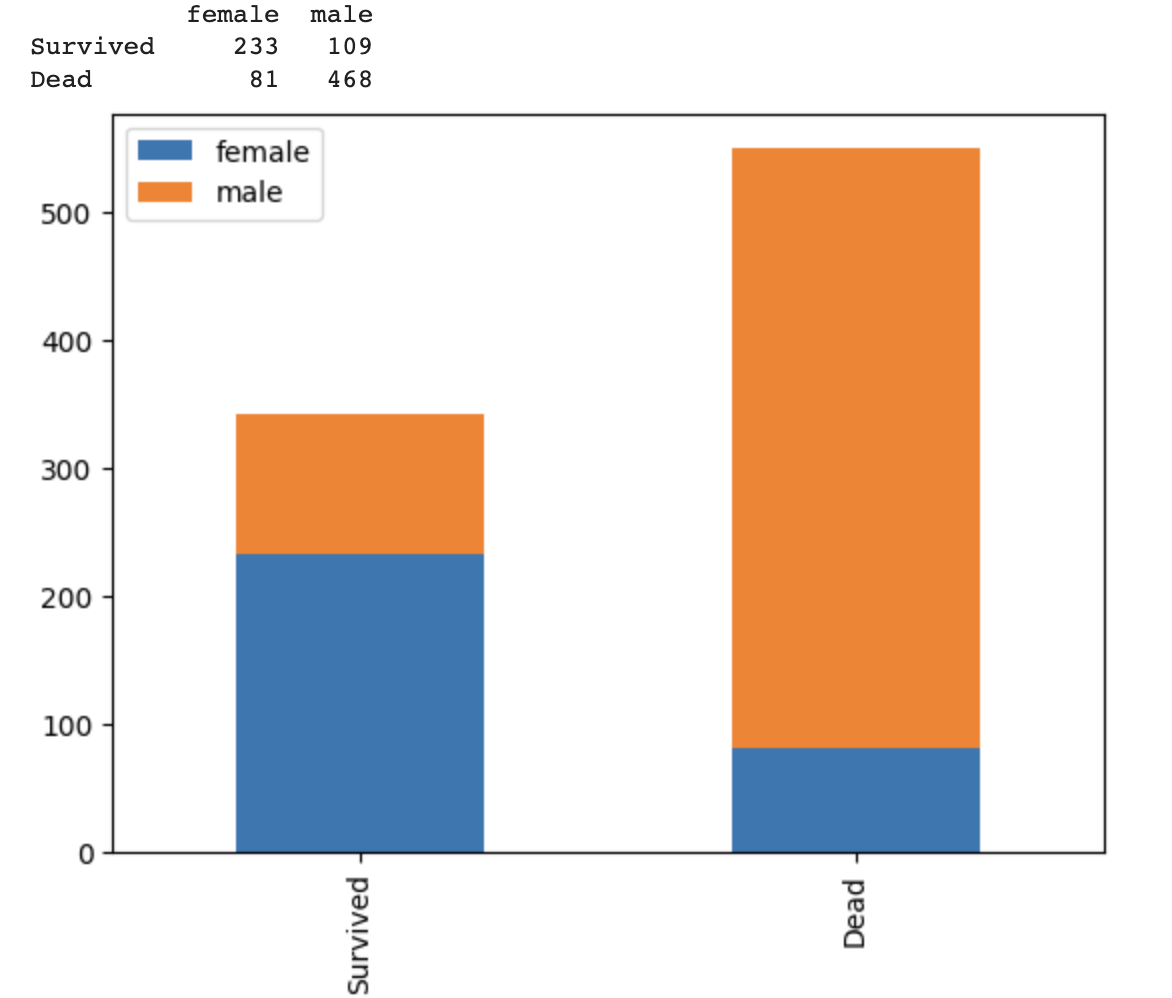
2. 좌석등급별 생존비율
show("Pclass")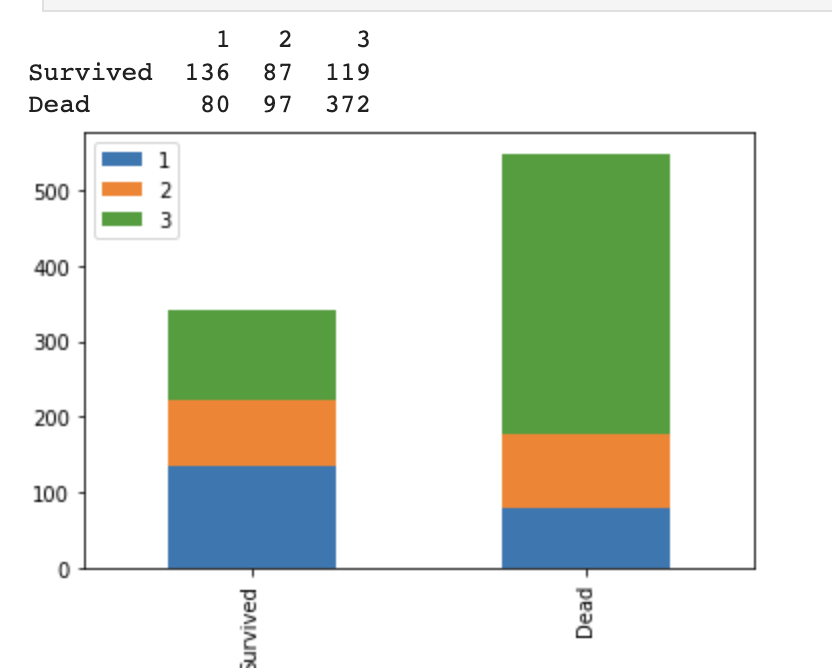
위와 같은 방식으로 데이터를 분석해 인사이트를 도출하는 것을, EDA(Exploratory Data Analysis, 탐색적 데이터 분석) 라고 부른다.
[데이터분석 기초] EDA의 개념과 데이터분석 잘 하는 법
오늘 포스팅 주제는 ‘데이터분석 기본 — EDA(Exploratory Data Analysis, 탐색적 데이터 분석)에 관하여 #데이터전처리 #결측치 #pandas’ 이다.
jalynne-kim.medium.com
데이터를 보고, 인사이트를 추출했으면, 예를 들어, Cabin 이나, Ticket 번호는 유의미하지 않다거나 등등
데이터를 전처리 해주어야한다.
2. 특징공학등을 활용한 데이터 전처리
import pandas as pd
train_dataset = pd.read_csv("titanic_train.csv")
test_dataset = pd.read_csv("titanic_test.csv")
train_dataset.head(10)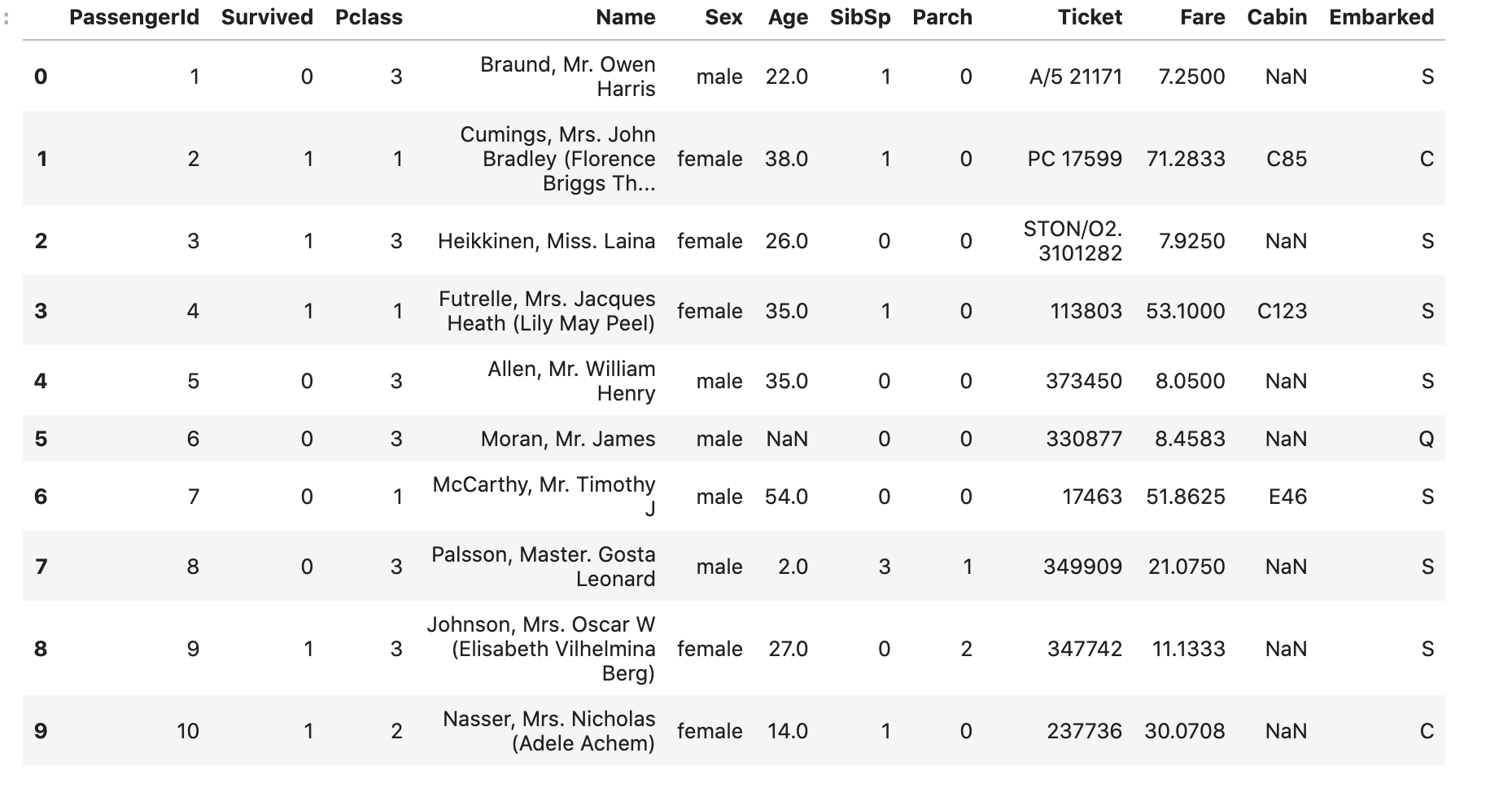
2-1 불필요 정보 제거하기
- 티켓의 번호(ticket)
- 방의 번호(cabin)
- 이름 정보(name)
(이름 정보에는 Mrs 등과 같은 호칭이 있어, 따로 처리해주어야하나, baseline 이므로 편의를 위해 삭제함)
train_dataset.drop("Ticket", axis=1, inplace=True)
train_dataset.drop("Cabin", axis=1, inplace=True)
train_dataset.drop("Name", axis=1, inplace=True)
train_dataset.head()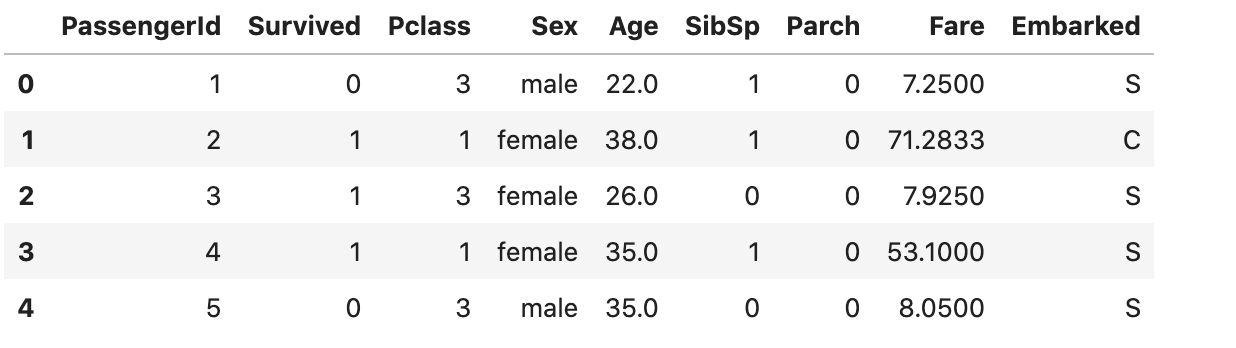
위처럼 했음, test data 도 반드시 지워줘야한다.
+) Inplace 속성 값이 True 이면 원본 데이터 프레임의 값이 직접 수정된다는 것임.
inplace = True 는 바로, 기존 데이터프레임에 변경된 설정으로 덮어쓰겠다는 의미를 가진답니다. 즉, inplace = True 를 입력하지 않으면 특정 변수에 저장하도록 코드를 입력해야 하는데, inplace = True를 사용하면 한번에 기존 변수에 덮어쓸 수 있습니다.
https://www.dinolabs.ai/70 <-- 참고
test_dataset.drop("Ticket", axis=1, inplace=True)
test_dataset.drop("Cabin", axis=1, inplace=True)
test_dataset.drop("Name", axis=1, inplace=True)test data 도 삭제해준다.
2-2 카테고리형 데이터를 수치형으로 변환하기
성별
m = {"female": 0, "male": 1}
train_dataset["Sex"] = train_dataset["Sex"].map(m)
test_dataset["Sex"] = test_dataset["Sex"].map(m)
train_dataset.head()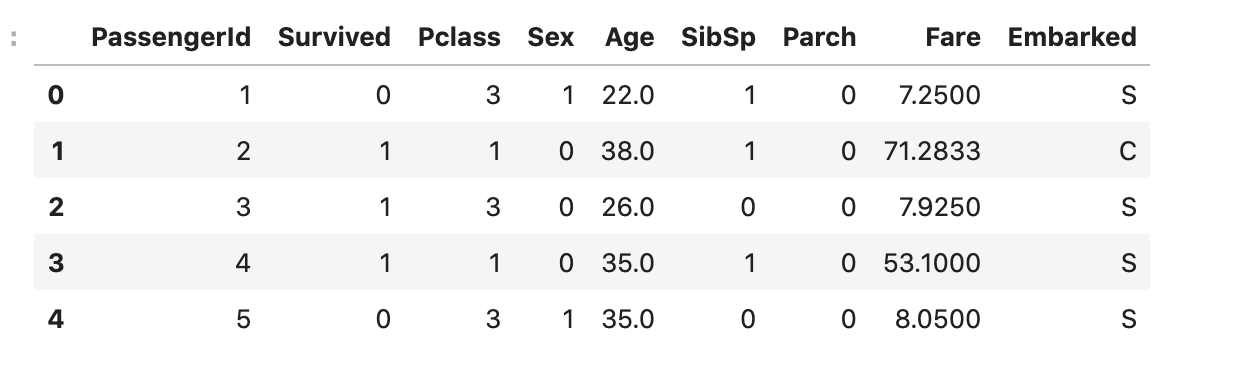
선착장
m = {"S": 0, "C": 1, "Q": 2}
train_dataset["Embarked"] = train_dataset["Embarked"].map(m)
test_dataset["Embarked"] = test_dataset["Embarked"].map(m)
train_dataset.head()
2-3 missing value 처리하기
Age, Fare -> 평균값으로
선착장 정보는 2개만 missing 이므로 그냥 제거
train_dataset["Age"].fillna(train_dataset["Age"].mean(), inplace=True)
test_dataset["Age"].fillna(test_dataset["Age"].mean(), inplace=True)
train_dataset["Fare"].fillna(train_dataset["Fare"].mean(), inplace=True)
test_dataset["Fare"].fillna(test_dataset["Fare"].mean(), inplace=True)
train_dataset.dropna(inplace=True)
train_dataset.info()
test_dataset.info()
결과적으로 모든 학습/테스트 데이터에 결측값 제거 완료
2-4 나이 & 요금 구간 설정하기
- 특정한 컬럼(column)의 요약된 정보를 확인하기 위해 describe() 메서드를 사용할 수 있음
- 학습 데이터의 나이(age) 구간을 확인할 수 있음.
- 평균 나이(average age): 29.65
- 최소 나이(min age): 0.42
- 최대 나이(max age): 80.00
- qcut() 메서드는 데이터의 값에 대하여 구간별로 잘라내어 레이블을 할당
- 나이(age) 속성에 대하여 구간화(binning)를 진행
train_dataset["Age"] = pd.qcut(train_dataset["Age"], 4, labels=[0, 1, 2, 3])
test_dataset["Age"] = pd.qcut(test_dataset["Age"], 4, labels=[0, 1, 2, 3])
train_dataset["Fare"] = pd.qcut(train_dataset["Fare"], 4, labels=[0, 1, 2, 3])
test_dataset["Fare"] = pd.qcut(test_dataset["Fare"], 4, labels=[0, 1, 2, 3])
전처리된 데이터를 따로 저장해주었음.
train_dataset.to_csv("titanic_train_processed.csv", index=False)
test_dataset.to_csv("titanic_test_processed.csv", index=False)
3. 타이타닉 모델 학습하기
import pandas as pd
train_dataset = pd.read_csv('titanic_train_processed.csv')
test_dataset = pd.read_csv('titanic_test_processed.csv')
train_dataset.head()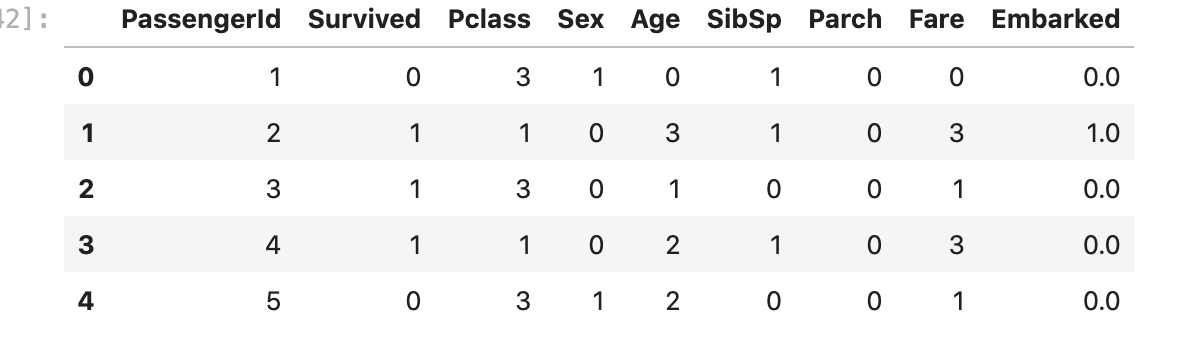
- 가장 먼저 탑승객 번호(passenger id)는 입력 특징에서 제외 -> 탑승객 번호를 인덱스(index)로 사용할 수 있음
- 생존 여부(survived)는 별도의 정답 레이블로 구분하여 사용
label = train_dataset['Survived']
train_dataset.drop("Survived", axis=1, inplace=True)
train_dataset.set_index('PassengerId', inplace=True)
test_dataset.set_index('PassengerId', inplace=True)
train_dataset.head()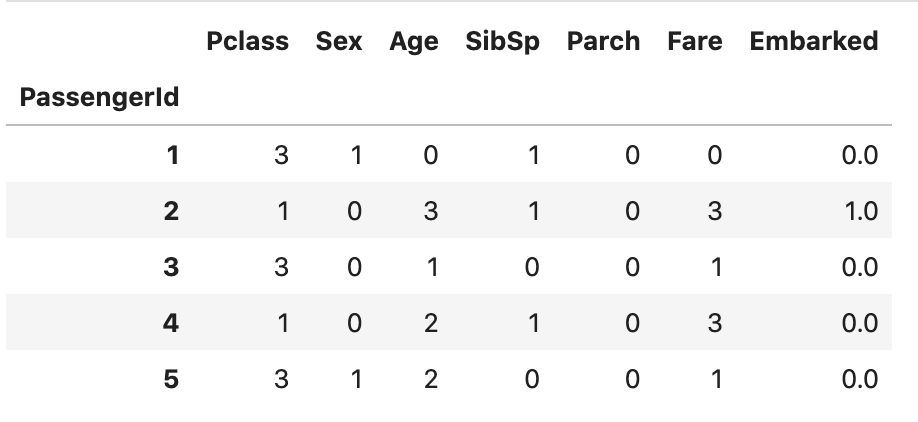
모델학습하기
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_scorek_fold = KFold(n_splits=5, shuffle=True, random_state=1234)
1. DecisionTree
clf = DecisionTreeClassifier()
scoring = 'accuracy'
score = cross_val_score(clf, train_dataset, label, cv=k_fold, n_jobs=1, scoring=scoring)
print(score)
print("점수 평균 : " + str(round(np.mean(score) * 100, 2)))[0.79775281 0.81460674 0.75842697 0.73033708 0.83615819]
점수 평균 : 78.752. RandomForestTree
clf = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1234)
scoring = 'accuracy'
score = cross_val_score(clf, train_dataset, label, cv=k_fold, n_jobs=1, scoring=scoring)
print(score)
print("점수 평균 : " + str(round(np.mean(score) * 100, 2)))[0.80337079 0.80337079 0.79775281 0.75842697 0.82485876]
점수 평균 : 79.76
제출용 파일 만들기
clf = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1234)
clf.fit(train_dataset, label)
prediction = clf.predict(test_dataset)
pred = pd.DataFrame({"PassengerId" : test_dataset.index, "Survived" : prediction})
pred.head(10)pred.to_csv('my_submission.csv', index=False)
4. Kaggle에 제출하기
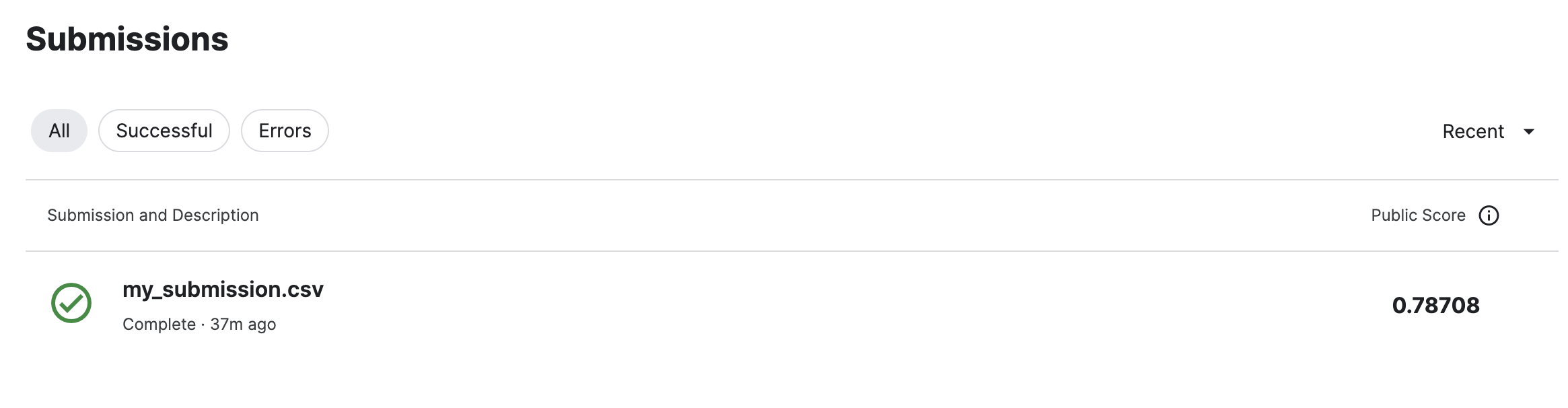
1800여등 함!
'인공지능공부' 카테고리의 다른 글
| CNN을 활용한 MNIST 분류 모델 구현 (0) | 2023.08.15 |
|---|---|
| DNN을 활용한 MNIST 분류 모델 구현 (0) | 2023.08.07 |
| 다변수 선형회귀, Multivariable Linear Regression Pytorch 구현하기 (0) | 2023.07.23 |
| Linear Regression Pytorch 로 구현하기 (0) | 2023.07.23 |
| Linear Regression 밑바닥부터 구현하기2 ( bias 포함 ) (0) | 2023.07.23 |


