
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 코딩애플
- AI
- Computer Vision
- 42서울
- 선형회귀
- 플러터
- 데이터분석
- 앱개발
- 인공지능
- 크롤러
- mnist
- RNN
- pytorch
- CV
- 딥러닝
- map
- Regression
- 유데미
- 피플
- 크롤링
- 자연어처리
- 회귀
- 머신러닝
- 지정헌혈
- filtering
- Flutter
- 파이썬
- 선형대수학
- 42경산
- 모델
- Today
- Total
David의 개발 이야기!
Linear Regression Pytorch 로 구현하기 본문
지난 포스팅에서 Linear Regression 의 bias 있을때, 없을때 여부에 따라, 밑바닥부터 구현해보았다.
2023.07.14 - [인공지능공부] - Linear Regression 바닥부터 구현하기 ( bias 없을때 )
Linear Regression 바닥부터 구현하기 ( bias 없을때 )
이런 문제를 해결하기 위해, Linear Regression 을 공부해보자. 우선 이번 포스팅에서는, Linear Regression 을 바닥부터 손수 구현해보고자 한다. 1. 주어진 데이터 시각화하기 import matplotlib.pyplot as plt X = [
david-kim2028.tistory.com
2023.07.23 - [인공지능공부] - Linear Regression 밑바닥부터 구현하기2 ( bias 포함 )
Linear Regression 밑바닥부터 구현하기2 ( bias 포함 )
금번 포스팅에서는 Linear Regression 에서, bias 가 있을때를 구현해본다. 큰 개념은 앞 포스팅과 동일하다 2023.07.14 - [인공지능공부] - Linear Regression 바닥부터 구현하기 ( bias 없을때 ) Linear Regression 바
david-kim2028.tistory.com
금번 포스팅에서는, 최근들어 핫한(요즘엔 아무도 tensorflow 안쓰는것 같아요ㅠㅠ) Pytorch 로 구현해보고자 한다.
* 용어정리
Pytorch 에서는, 모델, 입력 스칼라, 벡터, 행렬, 텐서도 모두 tensor 라고 부른다.
1. Pytorch 를 사용하기 위한 데이터 변환
import torch
X = [1, 2, 3, 4, 5, 6, 7] # 차원: [7]
Y = [25000, 55000, 75000, 110000, 128000, 155000, 180000] # 차원: [7]
X = [[i] for i in X] # 차원: [7, 1] = [batch_size, dim]
Y = [[i] for i in Y] # 차원: [7, 1] = [batch_size, dim]
x_data = torch.Tensor(X) # [batch_size, dim]
y_data = torch.Tensor(Y) # [batch_size, dim]
print(x_data.shape)
print(y_data.shape)참고) 이미지 일경우, 데이터의 차원이 [c, h, w]이므로, 입력은 [batch_size, c, h, w] 차원이다.
2. 모델 만들기
class LinearRegressionModel(torch.nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
# [1, 1]
self.linear = torch.nn.Linear(input_dim, output_dim)
def forward(self, x):
# x = [7, 1]
y_pred = self.linear(x) # [7, 1] * [1, 1] = [7, 1]
return y_pred
model = LinearRegressionModel(1, 1)[코드 설명]
torch.nn.Module : __init__(), forward() 를 우리가 작성할 수 있게 해줌
- 하나의 뉴럴 네트워크, 모델 그 자체를 의미
- __init__() : 해당 모델의 가중치 파라미너(w)를 넣어줌
torch.nn.Module은 PyTorch에서 딥러닝 모델을 구현하는데 사용되는 기본적인 클래스입니다. 이 클래스를 상속받아 사용하면 모델의 구조와 파라미터를 추적하고, 모델을 학습시키거나 추론하는데 필요한 다양한 기능을 활용할 수 있습니다. torch.nn.Module 클래스는 PyTorch의 신경망 모델을 정의하는데 중요한 역할을 합니다. 딥러닝 모델은 여러 층으로 구성되며, 각 층은 가중치와 편향을 포함한 학습 가능한 파라미터들을 갖습니다. 이러한 층과 파라미터들을 효율적으로 관리하고 추적하기 위해 torch.nn.Module 클래스를 사용합니다.
torch.nn.Module을 상속받은 클래스는 다음과 같은 주요 기능들을 사용할 수 있습니다:
파라미터 관리: nn.Module은 parameters() 메서드를 통해 모델 내의 모든 학습 가능한 파라미터들을 추적하고 관리합니다.순전파(forward pass) 정의: 모델의 forward() 메서드를 구현하여 입력 데이터를 받아 순전파 연산을 수행합니다. 순전파는 입력으로부터 출력까지의 계산 과정을 정의하는데 사용됩니다.모델 저장 및 불러오기: torch.nn.Module을 상속받은 모델은 편리하게 모델을 저장하고 불러올 수 있는 기능을 제공합니다.모델 학습 및 추론 관련 기능: nn.Module은 학습 시에는 손실 함수를 계산하고, 역전파를 수행하여 그래디언트를 업데이트하며, 추론 시에는 모델의 출력을 계산하는 등의 기능을 지원합니다.
따라서 torch.nn.Module은 PyTorch에서 딥러닝 모델을 정의하고 사용하는데 필수적인 클래스로, 이를 상속받아서 신경망 모델을 구현하게 됩니다.
self.linear = torch.nn.Linear(input_dim, output_dim)
self.linear = torch.nn.Linear(input_dim, output_dim) 구문은 선형 회귀 모델에서 사용되는 선형 레이어(Linear Layer)를 정의하는 역할을 합니다. 선형 레이어는 딥러닝에서 매우 중요한 구성 요소 중 하나로, 다음과 같은 역할을 수행합니다.
가중치와 편향의 초기화:선형 레이어는 입력 데이터와 출력 데이터 간의 선형 관계를 표현하는 함수를 학습하는데 사용됩니다.이러한 함수는 일반적으로 y = wx + b와 같은 형태로 표현됩니다. 여기서 w는 가중치(Weight)를, b는 편향(Bias)를 나타냅니다.선형 레이어를 정의할 때, input_dim은 입력 데이터의 차원, output_dim은 출력 데이터의 차원을 나타냅니다.torch.nn.Linear(input_dim, output_dim)를 통해 선형 레이어를 정의하면 내부적으로 가중치와 편향이 초기화되고, 학습 과정에서 이러한 파라미터들이 업데이트됩니다.
순전파 연산:선형 레이어는 입력 데이터를 받아 선형 변환을 수행하고, 출력 데이터를 계산하는 역할을 합니다. forward 메서드에서 self.linear(x)를 호출하여 입력 데이터 x를 선형 레이어에 통과시키면, 선형 변환된 결과인 y_pred를 얻게 됩니다.
학습 가능한 파라미터 관리: 선형 레이어는 학습 가능한 파라미터인 가중치 w와 편향 b를 갖습니다. 이러한 파라미터들은 학습 과정에서 업데이트되어 입력과 출력 간의 선형 관계를 학습하게 됩니다.torch.nn.Linear 클래스를 사용하면 모델의 학습 가능한 파라미터들을 자동으로 추적하고 업데이트하는데 도움을 줍니다.
따라서 self.linear = torch.nn.Linear(input_dim, output_dim)를 통해 선형 레이어를 정의하는 것은 선형 회귀 모델의 핵심 구성 요소를 설정하고, 학습 가능한 파라미터들을 관리하며, 입력과 출력 간의 선형 관계를 학습하기 위한 기능을 수행하는 것입니다. 이를 통해 선형 회귀 모델이 주어진 데이터에 가장 잘 맞는 가중치와 편향을 학습할 수 있게 됩니다.
super(LinearRegressionModel, self).__init__()
super()는 상속관계에 있는 부모 클래스의 생성자를 호출하는 함수.
LinearRegressionModel 클래스는 torch.nn.Module 클래스를 상속받고 있음. 따라서 super(~~~).__init__()은 부모 클래스인 torch.nn.Module 의 생성자를 호출하여, 초기화하는 역할을 함.
즉, LinearRegressionModel 클래스의 생성자(__init__ 메서드)에서는 먼저 torch.nn.Module 클래스의 생성자를 호출하여 기본적인 초기화 작업을 수행한 후에, 추가적인 초기화 작업을 진행할 수 있도록 함.
상속 관계에 있는 클래스에서 자식 클래스의 생성자에서 super().__init__()을 호출하면, 부모 클래스의 생성자를 먼저 실행하고, 그 후에 자식 클래스의 생성자 코드가 실행됨.
이렇게 함으로써 부모 클래스의 기능을 유지하면서 자식 클래스에서 필요한 추가 작업을 수행할 수 있음.
이런 방식으로 코드의 재사용성과 모듈화를 높일 수 있음.
3. 학습시키기
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
for epoch in range(10001):
# 항상 4단계로 구성됨
pred_y = model(x_data) # 1단계: 모델에 입력을 넣기
loss = criterion(pred_y, y_data) # 2단계: 손실 계산 "(모델 출력 - 실제 값)^2의 평균"
# 3단계: 현재 가지고 있는 모든 가중치에 대해서 기울기(gradient) 값을 0으로 초기화하고, 새롭게 계산
optimizer.zero_grad() # 기울기 0으로 초기화 (안 하면 계속 누적해서 더해짐, 그래서 꼭 해주셈)
loss.backward() # 기울기 계산 → 얘를 거치면 기울기 값이 어차피 0이 아닌 값이 됨(학습이 다 끝나기 전까지)
# 4단계: 계산된 기울기로 가중치 업데이트
optimizer.step()
if epoch % 1000 == 0:
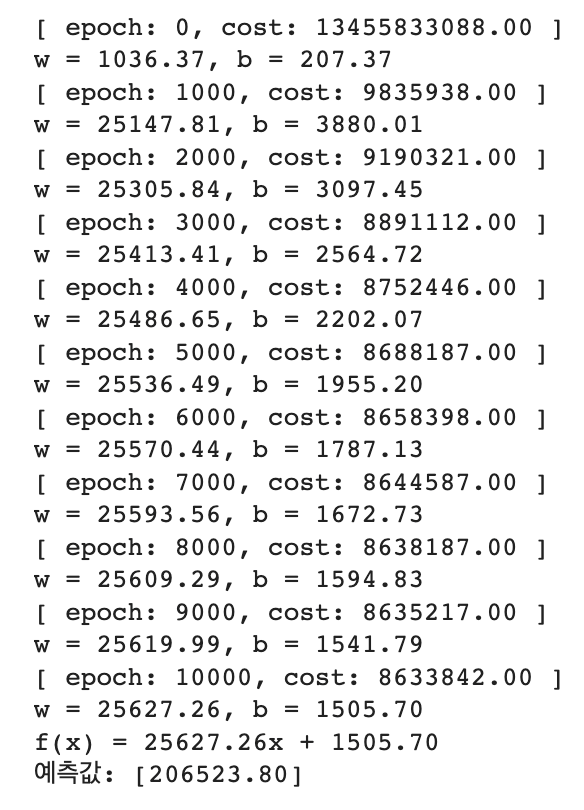
print("[ epoch: %d, cost: %.2f ]" % (epoch, loss.data))
print("w = %.2f, b = %.2f" % (model.linear.weight, model.linear.bias))
print("f(x) = %.2fx + %.2f" % (model.linear.weight, model.linear.bias))
print("예측값: [%.2f]" % (model(torch.Tensor([[8]]))))[코드 설명]
criterion : 비용(cost)를 말함. 여기에선 MSE 를 사용
optimizer : 여기에선 SGD를 사용 (이론에서 배우는 GD(경사하강법)을 mini-batch 단위로 수행)
[모델 학습시키는 순서]
만약에 전체 epoch 가 200번이고, 각 epoch 마다 mini-batch(step)이 100번이라면,
for epoch in range(200):
for step in range(100):
# 전체 데이터에서 mini-batch 단위로 뽑아서 모델 학습시키기
1) 모델 입력 # pred_y = model(x_data)
2) 손실 계산 # loss = criterion(pred_y, y_data)
3) 기울기 초기화 및 계산 # optimizer.zero_grad() & loss.backward()
4) 모델 업데이트 # optimizer.step()- for epoch in range(10001): 이후의 코드 블록은 총 10001 에포크(epoch) 동안 모델을 학습
- pred_y = model(x_data)를 통해 모델에 입력 데이터 x_data를 넣어 예측값 pred_y를 계산
- 이후 손실 함수를 사용하여 예측값과 실제값 y_data 사이의 오차를 계산합니다. 이 값은 loss에 저장
- optimizer.zero_grad()를 호출하여 현재 가지고 있는 모든 가중치에 대해서 기울기(gradient) 값을 0으로 초기화 ( 이는 새롭게 기울기를 계산하기 전에 기존의 기울기 값이 누적되지 않도록 하기 위함)
- loss.backward()를 호출하여 손실에 대한 기울기(gradient)를 계산( 이 과정에서 모델 내의 파라미터들에 대한 기울기가 계산되고, 이를 통해 모델이 얼마나 학습되어야 하는지를 알 수 있음)
- optimizer.step()을 호출하여 계산된 기울기로 가중치와 편향을 업데이트 이 과정에서 모델의 파라미터가 학습
'인공지능공부' 카테고리의 다른 글
| [기계학습 입문] 타이타닉 생존자 예측 모델 Baseline 구축하기 (1) | 2023.07.23 |
|---|---|
| 다변수 선형회귀, Multivariable Linear Regression Pytorch 구현하기 (0) | 2023.07.23 |
| Linear Regression 밑바닥부터 구현하기2 ( bias 포함 ) (0) | 2023.07.23 |
| Linear Regression 바닥부터 구현하기 ( bias 없을때 ) (0) | 2023.07.14 |
| Matplotlib 에 대해 알아보자! (0) | 2023.07.07 |


