
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 피플
- Computer Vision
- 모델
- 코딩애플
- AI
- map
- Regression
- 데이터분석
- 크롤러
- 앱개발
- filtering
- 선형회귀
- CV
- Flutter
- 플러터
- RNN
- 지정헌혈
- 42서울
- 42경산
- 인공지능
- pytorch
- 딥러닝
- 머신러닝
- mnist
- 유데미
- 회귀
- 크롤링
- 파이썬
- 선형대수학
- 자연어처리
Archives
- Today
- Total
David의 개발 이야기!
Linear Regression 밑바닥부터 구현하기2 ( bias 포함 ) 본문
반응형
금번 포스팅에서는 Linear Regression 에서, bias 가 있을때를 구현해본다.
큰 개념은 앞 포스팅과 동일하다
2023.07.14 - [인공지능공부] - Linear Regression 바닥부터 구현하기 ( bias 없을때 )
Linear Regression 바닥부터 구현하기 ( bias 없을때 )
이런 문제를 해결하기 위해, Linear Regression 을 공부해보자. 우선 이번 포스팅에서는, Linear Regression 을 바닥부터 손수 구현해보고자 한다. 1. 주어진 데이터 시각화하기 import matplotlib.pyplot as plt X = [
david-kim2028.tistory.com
다만 bias 가 생겼기 때문에, bias 를 기준으로 편미분 하는 로직이 추가 되었다.
1. 데이터 확인
import matplotlib.pyplot as plt
X = [1, 2, 3, 4, 5, 6, 7]
Y = [25000, 55000, 75000, 110000, 128000, 155000, 180000]
plt.plot(X, Y)
plt.scatter(X, Y)
2. 모델 구현
class H():
def __init__(self, w, b):
self.w = w
self.b = b
def forward(self, x):
return self.w * x + self.b
def get_cost(self, X, Y):
cost = 0
for i in range(len(X)):
cost += (self.forward(X[i]) - Y[i]) ** 2
cost = cost / len(X) #MSE 개념이니 Len(X)로 나누어준것임
return cost
def get_gradient_using_derivative(self, X, Y):
w_gradient = 0
b_gradient = 0
for i in range(len(X)):
w_gradient += (self.forward(X[i]) - Y[i]) * X[i]
b_gradient += (self.forward(X[i]) - Y[i])
w_gradient = 2 * w_gradient / len(X)
b_gradient = 2 * b_gradient / len(X) # gradient 를 Len(X)로 나눠주는 이유 -> cost를 미분한건데, cost 는 MSE 개념이니까
return w_gradient, b_gradient, self.get_cost(X, Y)
# w 값을 변경하는 함수
def set_w(self, w):
self.w = w
# w 값을 반환하는 함수
def get_w(self):
return self.w
# b 값을 변경하는 함수
def set_b(self, b):
self.b = b
# b 값을 반환하는 함수
def get_b(self):
return self.b-> 이차함수인 cost 함수를 최소화하도록 만드는 w, b 값을 찾는 것이다.
-> 따라서 cost 함수를 w, b에 대해 각각 편미분하여, 값을 찾아낸다.
3. 결과
w = 4
b = 0
h = H(w, b)
learning_rate = 0.001
for i in range(10001):
w_gradient, b_gradient, cost = h.get_gradient_using_derivative(X, Y)
h.set_w(h.get_w() + learning_rate * -w_gradient)
h.set_b(h.get_b() + learning_rate * -b_gradient)
if i % 1000 == 0:
print("[ epoch: %d, cost: %.2f ]" % (i, cost))
print("w = %.2f, w_gradient = %.2f" % (h.get_w(), w_gradient))
print("b = %.2f, b_gradient = %.2f" % (h.get_b(), b_gradient))
print("f(x) = %.2fx + %.2f" %(h.get_w(), h.get_b()))
print("예측값: [%.2f]" %(h.forward(8)))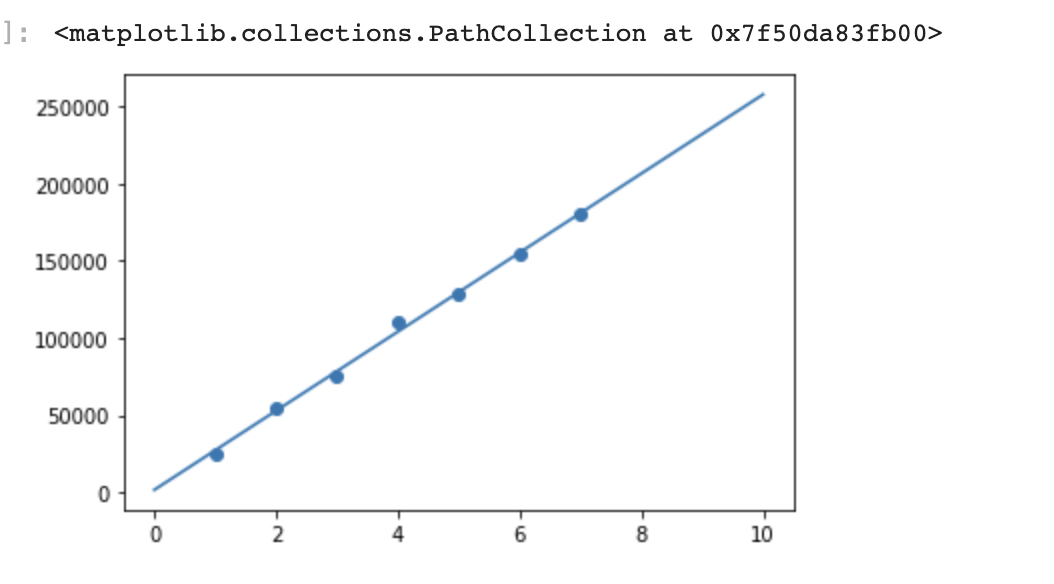
반응형
'인공지능공부' 카테고리의 다른 글
| 다변수 선형회귀, Multivariable Linear Regression Pytorch 구현하기 (0) | 2023.07.23 |
|---|---|
| Linear Regression Pytorch 로 구현하기 (0) | 2023.07.23 |
| Linear Regression 바닥부터 구현하기 ( bias 없을때 ) (0) | 2023.07.14 |
| Matplotlib 에 대해 알아보자! (0) | 2023.07.07 |
| Pandas 에 대해 알아보자 feat. Series, DataFrame (0) | 2023.07.07 |
'인공지능공부' Related Articles
more


