
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 크롤링
- Computer Vision
- map
- 모델
- 유데미
- 크롤러
- 인공지능
- 파이썬
- AI
- pytorch
- 선형대수학
- 데이터분석
- 딥러닝
- RNN
- CV
- 자연어처리
- 42경산
- 앱개발
- Regression
- 머신러닝
- mnist
- 지정헌혈
- Flutter
- 회귀
- 42서울
- 피플
- 선형회귀
- filtering
- 플러터
- 코딩애플
- Today
- Total
David의 개발 이야기!
Pandas 에 대해 알아보자 feat. Series, DataFrame 본문
0. Pandas 란?
- 데이터를 효과적으로 처리하고, 보여줄 수 있도록 도와주는 라이브러리
- Numpy 와 함께 사용되어 다양한 연계적인 기능을 제공
- Index 에 따라 데이터를 나열하므로 Dictionary 자료형에 가까움
- Series를 기본적인 자료형으로 사용
- Excel 과 유사
1. Series 란?
- Series 는 인덱스와 값으로 구성됌.
- Excel 에서의 Column과 유사
import pandas as pd
array = pd.Series(['사과', '바나나', '당근'], index=['a', 'b', 'c'])
print(array)
print(array['a'])a 사과
b 바나나
c 당근
dtype: object
사과
import pandas as pd
data = {
'a': '사과',
'b': '바나나',
'c': '당근' }
# Dict 자료형을 Series로 바꾸기
array = pd.Series(data)
print(array['a'])
시리즈(Series)는 인덱스(Index)에 따라 데이터를 구분 하므로 사전(Dictionary) 자료형에 가까움.
2. Data Frame 이란?
- 다수의 Series 를 모아 처리하기 위한 목적으로 사용함.
- 표 형태로 데이터를 손쉽게 출력하고자 할때, 사용할 수 있음.
- 하나의 Excel 시트 와 유사.
import pandas as pd
word_dict = {
'Apple': '사과',
'Banana': '바나나',
'Carrot': '당근'
}
frequency_dict = {
'Apple': 3,
'Banana': 5,
'Carrot': 7
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict)
# 이름(Name): 값(Values)
summary = pd.DataFrame({
'word': word,
'frequency': frequency
})
print(summary)word frequency
Apple 사과 3
Banana 바나나 5
Carrot 당근 7
3. Series 연산
- 시리즈를 서로 연산해서 새로운 시리즈를 만들 수 있음.

import pandas as pd
word_dict = {
'Apple': '사과',
'Banana': '바나나',
'Carrot': '당근'
}
frequency_dict = {
'Apple': 3,
'Banana': 5,
'Carrot': 7
}
importance_dict = {
'Apple': 3,
'Banana': 2,
'Carrot': 1
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict)
importance = pd.Series(importance_dict)
summary = pd.DataFrame({
'word': word,
'frequency': frequency,
'importance': importance
})
score = summary['frequency'] * summary['importance']
summary['score'] = score
print(summary)
4. DataFrame 의 슬라이싱
import pandas as pd
word_dict = {
'Apple': '사과',
'Banana': '바나나',
'Carrot': '당근',
'Durian': '두리안'
}
frequency_dict = {
'Apple': 3,
'Banana': 5,
'Carrot': 7,
'Durian': 2
}
importance_dict = {
'Apple': 3,
'Banana': 2,
'Carrot': 1,
'Durian': 1
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict)
importance = pd.Series(importance_dict)
summary = pd.DataFrame({
'word': word,
'frequency': frequency,
'importance': importance
})
print(summary)
# 이름을 기준으로 슬라이싱
print(summary.loc['Banana':'Carrot', 'importance':])
# 인덱스를 기준으로 슬라이싱
print(summary.iloc[1:3, 2:])
5. DataFrame 의 연산 - 데이터 변경 & 새 데이터 삽입
import pandas as pd
word_dict = {
'Apple': '사과',
'Banana': '바나나',
'Carrot': '당근',
'Durian': '두리안'
}
frequency_dict = {
'Apple': 3,
'Banana': 5,
'Carrot': 7,
'Durian': 2
}
importance_dict = {
'Apple': 3,
'Banana': 2,
'Carrot': 1,
'Durian': 1
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict)
importance = pd.Series(importance_dict)
summary = pd.DataFrame({
'word': word,
'frequency': frequency,
'importance': importance
})
print(summary)
summary.loc['Apple', 'importance'] = 5 # 데이터의 변경
summary.loc['Elderberry'] = ['엘더베리', 5, 3] # 새 데이터 삽입
print(summary)
5. DataFrame 엑셀로 내보내기 및 불러오기 ( csv 파일로 )
import pandas as pd
word_dict = {
'Apple': '사과',
'Banana': '바나나',
'Carrot': '당근'
}
frequency_dict = {
'Apple': 3,
'Banana': 5,
'Carrot': 7
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict)
summary = pd.DataFrame({
'word': word,
'frequency': frequency
})
summary.to_csv("summary.csv", encoding="utf-8-sig")
saved = pd.read_csv("summary.csv", index_col=0)
print(saved)
6. DataFrame 의 Null 여부 확인 - notnull() / isnull() / fillna()
import pandas as pd
import numpy as np
word_dict = {
'Apple': '사과',
'Banana': '바나나',
'Carrot': '당근',
'Durian': '두리안'
}
frequency_dict = {
'Apple': 3,
'Banana': 5,
'Carrot': np.nan,
'Durian': 2
}
importance_dict = {
'Apple': 3,
'Banana': 2,
'Carrot': 1,
'Durian': 1
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict)
importance = pd.Series(importance_dict)
summary = pd.DataFrame({
'word': word,
'frequency': frequency,
'importance': importance
})
print(summary)
print(summary.notnull())
print(summary.isnull())
summary['frequency'] = summary['frequency'].fillna('데이터 없음')
print(summary)
7. Series 합치기
import pandas as pd
array1 = pd.Series([1, 2, 3], index=['A', 'B', 'C'])
array2 = pd.Series([4, 5, 6], index=['B', 'C', 'D'])
array = array1.add(array2, fill_value=0)
print(array)A 1.0
B 6.0
C 8.0
D 6.0
dtype: float64
8. DataFrame 합치기
import pandas as pd
array1 = pd.DataFrame([[1, 2], [3, 4]], index=['A', 'B'])
array2 = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=['B', 'C', 'D'])
print(array1)
print(array2)
array = array1.add(array2, fill_value=0)
print(array)
9. DataFrame 집계함수
import pandas as pd
array1 = pd.DataFrame([[1, 2], [3, 4]], index=['A', 'B'])
array2 = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=['B', 'C', 'D'])
array = array1.add(array2, fill_value=0)
print(array)
print("컬럼 1의 합:", array[1].sum())
print(array.sum())
10. DataFrame 정렬 함수 - sort_values()
import pandas as pd
import numpy as np
word_dict = {
'Apple': '사과',
'Banana': '바나나',
'Carrot': '당근',
'Durian': '두리안'
}
frequency_dict = {
'Apple': 3,
'Banana': 5,
'Carrot': 1,
'Durian': 2
}
importance_dict = {
'Apple': 3,
'Banana': 2,
'Carrot': 1,
'Durian': 1
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict)
importance = pd.Series(importance_dict)
summary = pd.DataFrame({
'word': word,
'frequency': frequency,
'importance': importance
})
print(summary)
summary = summary.sort_values('frequency', ascending=False)
print(summary)
10. DataFrame 마스킹
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(1, 10, (2, 2)), index=[0, 1], columns=["A", "B"])
# 데이터 프레임 출력하기
print(df)
# 컬럼 A의 각 원소가 5보다 작거나 같은지 출력
print(df["A"] <= 5)
# 컬럼 A의 원소가 5보다 작고, 컬럼 B의 원소가 8보다 작은 행 추출
print(df.query("A <= 5 and B <= 8"))
11. DataFrame 개별연산
* apply 방법 & 함수 이용
import pandas as pd
df = pd.DataFrame([[1, 2, 3, 4], [1, 2, 3, 4]], index=[0, 1], columns=["A", "B", "C", "D"])
print(df)
df = df.apply(lambda x: x + 1)
print(df)
def addOne(x):
return x + 1
df = df.apply(addOne)
print(df)A B C D
0 1 2 3 4
1 1 2 3 4
A B C D
0 2 3 4 5
1 2 3 4 5
A B C D
0 3 4 5 6
1 3 4 5 6
* replace 이용
import pandas as pd
df = pd.DataFrame([
['Apple', 'Apple', 'Carrot', 'Banana'],
['Durian', 'Banana', 'Apple', 'Carrot']],
index=[0, 1],
columns=["A", "B", "C", "D"])
print(df)
df = df.replace({"Apple": "Airport"})
print(df)
12. DataFrame 그룹화
* groupby & sum 이용
import pandas as pd
df = pd.DataFrame([
['Apple', 7, 'Fruit'],
['Banana', 3, 'Fruit'],
['Beef', 5, 'Meal'],
['Kimchi', 4, 'Meal']],
columns=["Name", "Frequency", "Type"])
print(df)
print(df.groupby(['Type']).sum())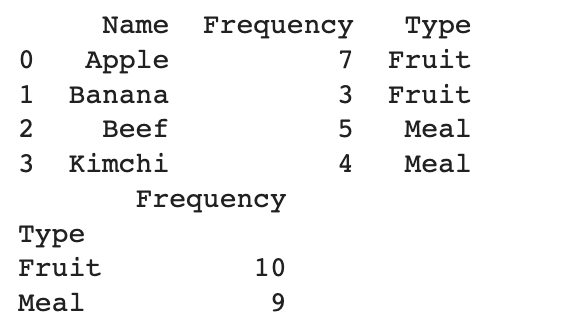
* groupby & aggregate 이용
import numpy as np
import pandas as pd
df = pd.DataFrame([
['Apple', 7, 5, 'Fruit'],
['Banana', 3, 6, 'Fruit'],
['Beef', 5, 2, 'Meal'],
['Kimchi', 4, 8, 'Meal']],
columns=["Name", "Frequency", "Importance", "Type"])
print(df)
print(df.groupby(["Type"]).aggregate([min, max, np.average]))
* 함수 & filter 이용
import pandas as pd
df = pd.DataFrame([
['Apple', 7, 5, 'Fruit'],
['Banana', 3, 6, 'Fruit'],
['Beef', 5, 2, 'Meal'],
['Kimchi', 4, 8, 'Meal']],
columns=["Name", "Frequency", "Importance", "Type"])
def my_filter(data):
return data["Frequency"].mean() >= 5
print(df)
df = df.groupby("Type").filter(my_filter)
print(df)
* groupby & get_group() 이용
import pandas as pd
df = pd.DataFrame([
['Apple', 7, 5, 'Fruit'],
['Banana', 3, 6, 'Fruit'],
['Beef', 5, 2, 'Meal'],
['Kimchi', 4, 8, 'Meal']],
columns=["Name", "Frequency", "Importance", "Type"])
df = df.groupby("Type").get_group("Fruit")
print(df)
* groupby & apply 이용
import pandas as pd
df = pd.DataFrame([
['Apple', 7, 5, 'Fruit'],
['Banana', 3, 6, 'Fruit'],
['Beef', 5, 2, 'Meal'],
['Kimchi', 4, 8, 'Meal']],
columns=["Name", "Frequency", "Importance", "Type"])
df["Gap"] = df.groupby("Type")["Frequency"].apply(lambda x: x - x.mean())
print(df)
12. DataFrame 다중화
import numpy as np
import pandas as pd
df = pd.DataFrame(
np.random.randint(1, 10, (4, 4)),
index=[['1차', '1차', '2차', '2차'], ['공격', '수비', '공격', '수비']],
columns=['1회', '2회', '3회', '4회']
)
print(df)
print(df[["1회", "2회"]].loc["2차"])
13. 피벗 테이블 기초
import numpy as np
import pandas as pd
df = pd.DataFrame([
['Apple', 7, 5, 'Fruit'],
['Banana', 3, 6, 'Fruit'],
['Coconut', 2, 6, 'Fruit'],
['Rice', 8, 2, 'Meal'],
['Beef', 5, 2, 'Meal'],
['Kimchi', 4, 8, 'Meal']],
columns=["Name", "Frequency", "Importance", "Type"])
print(df)
df = df.pivot_table(
index="Importance", columns="Type", values="Frequency",
aggfunc=np.max
)
print(df)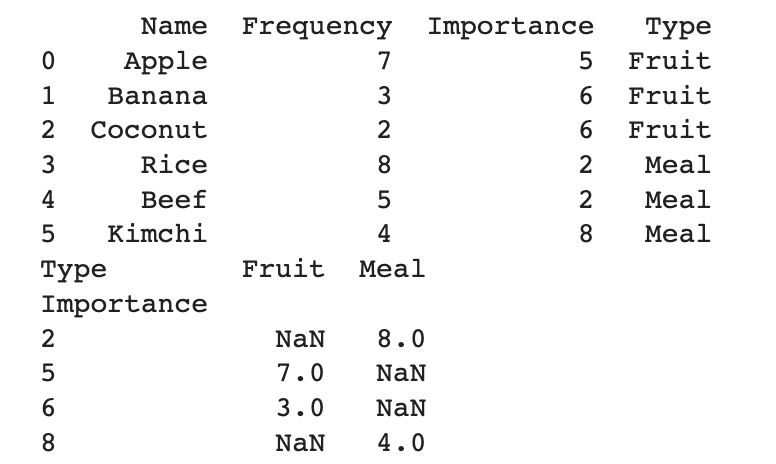
'인공지능공부' 카테고리의 다른 글
| Linear Regression 바닥부터 구현하기 ( bias 없을때 ) (0) | 2023.07.14 |
|---|---|
| Matplotlib 에 대해 알아보자! (0) | 2023.07.07 |
| OpenCV 에 대해 알아보자 (0) | 2023.07.07 |
| Numpy 에 대해 알아보자 (0) | 2023.07.05 |
| 활성화 함수가 필요한 이유는 무엇일까? (0) | 2022.01.16 |



