
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 데이터분석
- map
- 자연어처리
- Flutter
- mnist
- Computer Vision
- 코딩애플
- 피플
- 크롤링
- 지정헌혈
- CV
- AI
- Regression
- 모델
- 42서울
- 유데미
- 파이썬
- filtering
- 딥러닝
- 42경산
- 머신러닝
- 크롤러
- 선형회귀
- pytorch
- 선형대수학
- 회귀
- 플러터
- RNN
- 인공지능
- 앱개발
- Today
- Total
David의 개발 이야기!
[CV Lecture 07] Feature Detection (Cont.) 본문
1. Harris Corner Detector (Cont)
자 이전 포스팅까지, edge와 corner를 찾는 방법에 대해 배웠다. 우리는 지금 파노라마를 만드는 방법을 위한 기반을 공부하고 있는데, 어떻게 하면, 두 지점의 유사성을 판단할 수 있을까? 라는 질문을 던져보아야한다. 방법은 아래 이미지와 같다.

유사성을 판단하는 방법을 알게 되었으니, 그 다음으로 고민해야할 것은, "어떻게 독특한 고유의 patch를 찾을 것인가?" 이다. 모든 지점을 일일히 위와 같은 방식으로 계산하게 된다면, 엄청난 Computing Loss가 날 것이다. patch가 너무 많기 때문이다

그렇기 때문에, 우리는, 보통 local neighbor 만 고려하는 방식을 채택한다.

좋은 feature란, 자신을 유일하게 특정지을수 있는 것이기에, 좋은 local feature를 찾아야한다.
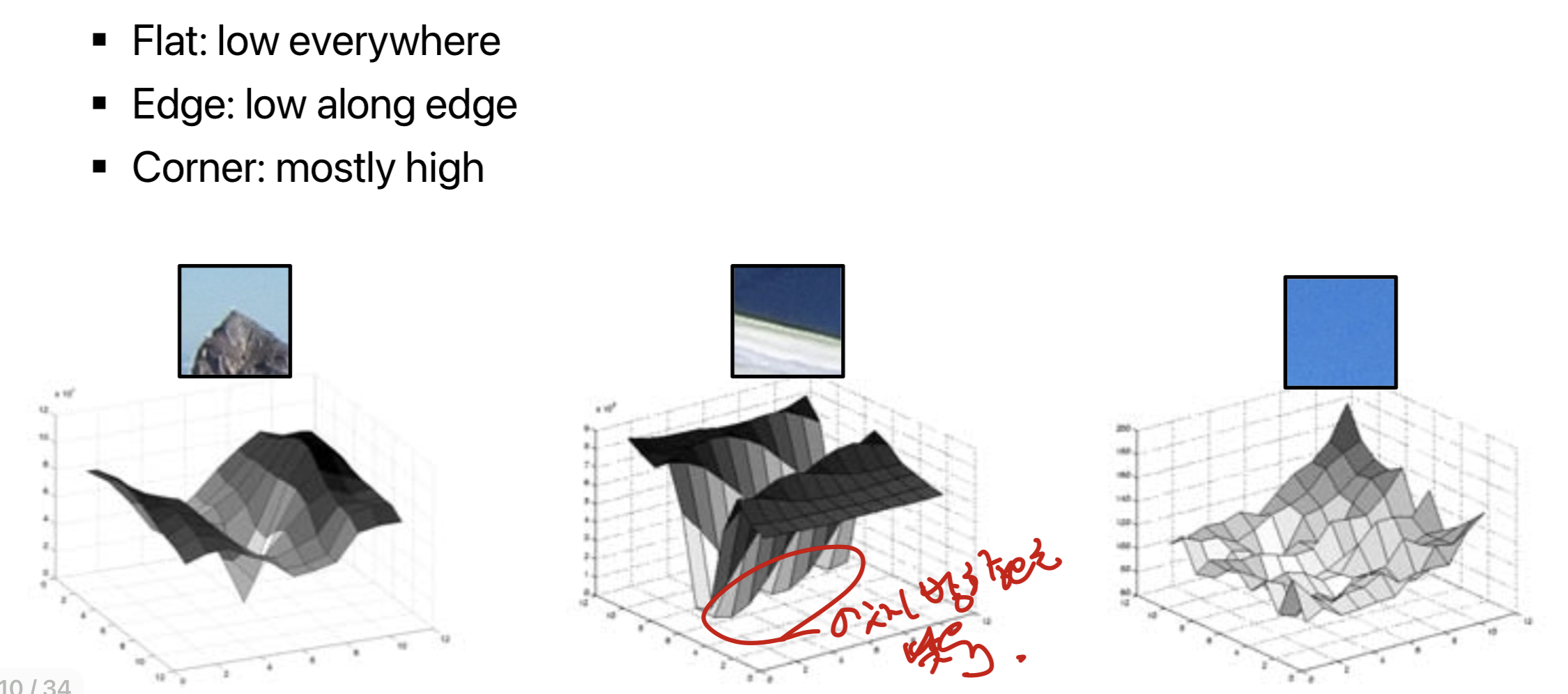
2. Scale-Invariance Feature Detection

하나의 필터만으로는 부족하다는 것을 알수 있다.

다양한 세타 값을 통해, maximum response를 찾아야 하며, 큰 이미지의 경우, downsample을 진행하여, 필터의 크기를 키우는 것과 같은 효과를 내기도 한다.

2-1 How to efficiently implement LoG filters?
실제 환경에서는, LoG 를 계산하는 것은 계산적으로 비용이 많이 든다 (2차미분을 하기 때문) 따라서, Difference of Gaussian 을 사용하기도 한다!! (Lecture 5에 있던 DoG, Derivative of Gaussian과 다른것이다!!!!!)
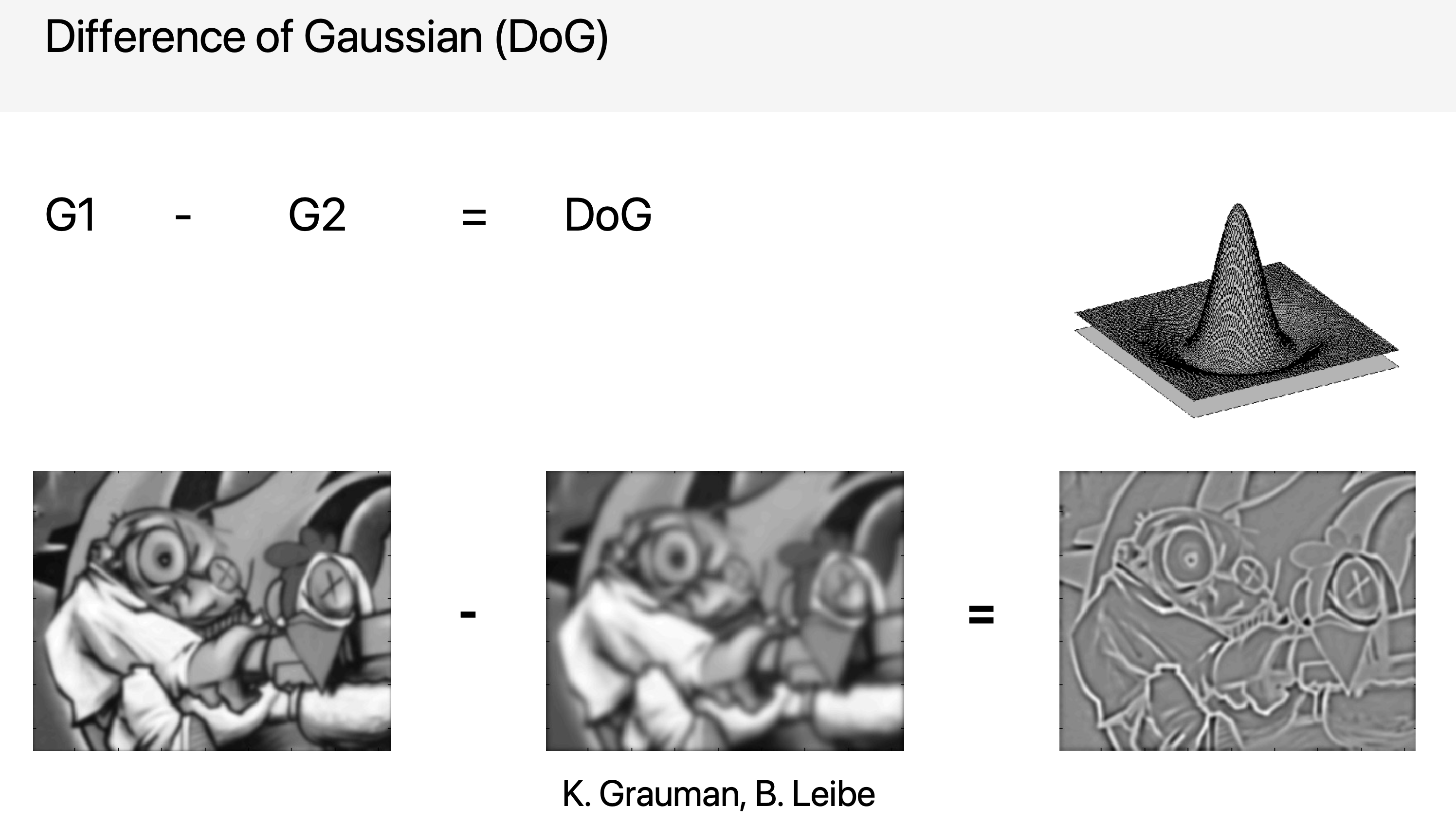
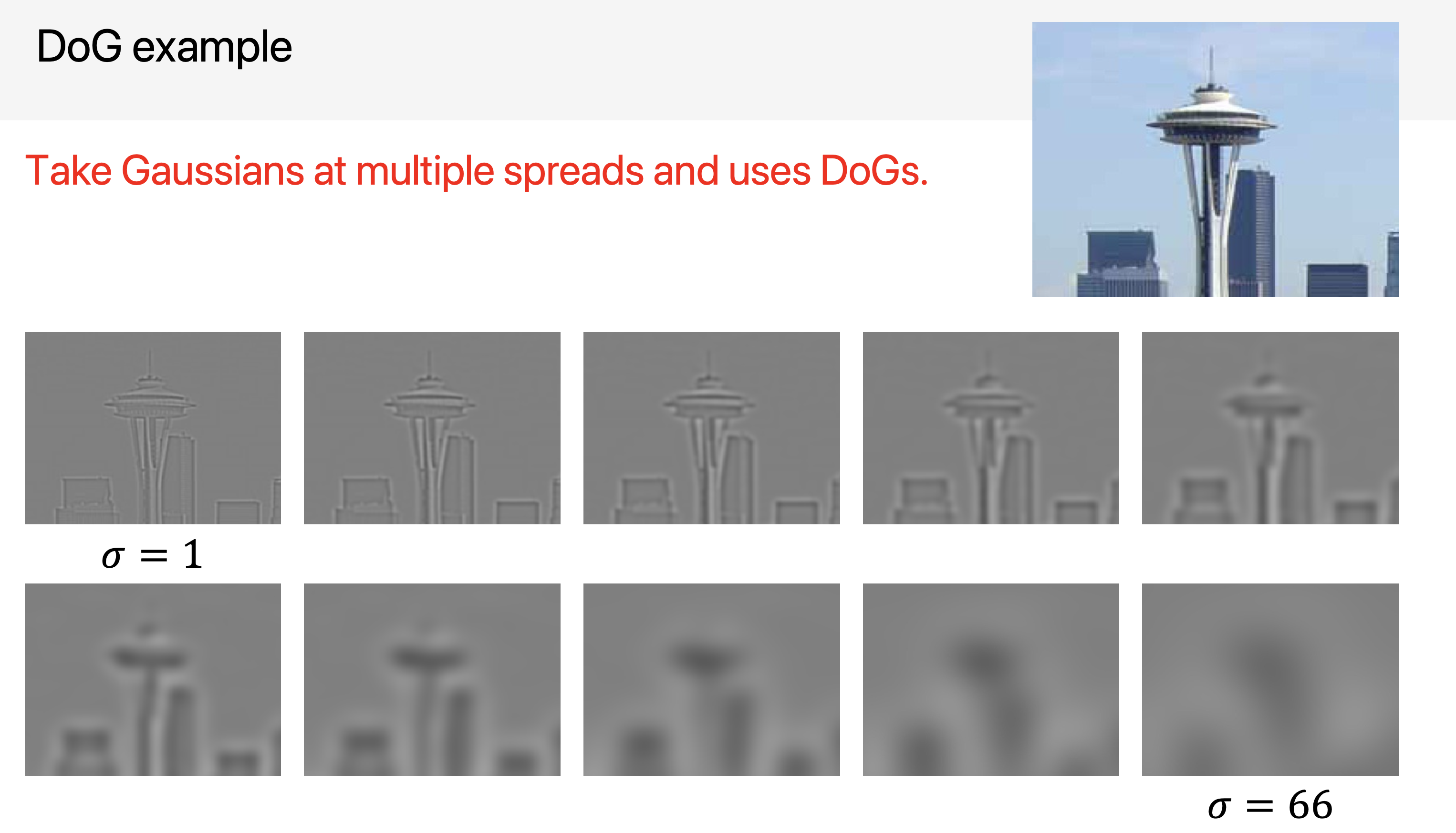
오늘은, Feature Detection 을 위한 추가적인 지식을 학습 할 수 있었다!
'컴퓨터비전' 카테고리의 다른 글
| [CV Lecture 09] Geometric Transformation (1) | 2023.12.17 |
|---|---|
| [CV Lecture 08] Feature Description, Feature Matching (0) | 2023.12.03 |
| [CV Lecture 06] Feature Detection (0) | 2023.12.03 |
| [CV Lecture 05] Edge Detection (0) | 2023.11.29 |
| [CV Lecture 04] Image - Resizing (1) | 2023.11.29 |



