
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- filtering
- 코딩애플
- 머신러닝
- 플러터
- 유데미
- 크롤링
- 선형회귀
- AI
- 42경산
- 피플
- 모델
- Regression
- mnist
- map
- CV
- 데이터분석
- Computer Vision
- 자연어처리
- 앱개발
- 딥러닝
- 인공지능
- 회귀
- 크롤러
- 42서울
- 선형대수학
- 파이썬
- pytorch
- RNN
- 지정헌혈
- Flutter
- Today
- Total
David의 개발 이야기!
[논문 리뷰] CLIP : Learning Transferable Visual Models From Natural Language Supervision 본문
[논문 리뷰] CLIP : Learning Transferable Visual Models From Natural Language Supervision
david.kim2028 2024. 2. 27. 13:11
원본 논문은 아래와 같다.
https://arxiv.org/abs/2103.00020
Learning Transferable Visual Models From Natural Language Supervision
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual co
arxiv.org
0. Abstract
일반적인 컴퓨터비전에서, 시각적 개념(텍스트데이터)를 받으려면, 추가적인 라벨링된 데이터가 필요하기 때문에, generality 와 usability 가 제한된다. 따라서, 이미지에 대한 raw data를 직접 학습하는 거은, 더 광범위한 자원(소스)를 활용하는 유망한 대안이라 할 수 있다. 인터넷에서 수집한 4억개(이미지, 텍스트)쌍의 데이터 세트에서 어떤 캡션이 어떤 이미지와 어울리는지 예측하는 간단한 사전학습작업(pre-training task)이 효율적이고 확장가능한 방법으로 SOTA 이미지 표현을 처음부터 학습할 수 있음을 보여준다.
30개가 넘는 기존 컴퓨터 비전 데이터 세트를 벤치마킹해서, 이 접근 방식의 성능을 연구했으며, OCR, 동영상 내 행위 인식, 지리적 위치파악(geo-localization) 및 다양한 유형의 세분화된 (fine-grained) 객체 분류와 같은 작업을 포괄한다.
이 모델은, 대부분의 작업에 별다른 어려움 없이 적용이 가능하며, 데이터 세트에 대한 특별한 학습 없이도, fully supervised baseline 과도 비슷한 성능이 도출된다. 예를 들어, 128만개의 훈련예제를 하나도 사용하지 않고도, ImageNet 제로샷에서 ResNet-50의 정확도와 일치한다.
+) CLIP의 등장배경 및 기존 방법의 문제점
CLIP이 발표된 시점은 2021년으로, Vision Model 과 Language Model, 두가지 카테고리로 발전이 되어가고 있었다.
Vision Model 은 어떻게 모델을 구성해야, 이미지를 입력받았을때 더 좋은 표현을 학습하는지가 주된 연구 포인트였다. 따라서, Inception, ResNet 과 같이 효율적으로 더 깊은 모델을 만드는 방법을 고민했다. SENet, BAM,CBAM 등은 어텐션 모듈을 사용하는 방법을 제시했다. 또, Visual Model 의 트렌드는 Transformer 구조를 적용하는것이었는데, 이러한 트렌드에 맞춰, ImageGPT, Vision Transformer 등이 발표되었다.
하지만, 이미지만 학습한 모델은 일반화 능력이 부족하고, 노이즈들에 취약한 문제들이 있었다.
Language Model 은 2017년 Transformer 의 발표에 힘입고, 큰 발전을 이루었는데, 트랜스포머 구조로 긴문장도 효과적으로 처리할 수 있게 되었다. 이후 GPT-1,2,3,4 BERT등 다양한 초거대언어모델 (Large Language Model)이 발표되며, LLM가 대세가 되었다.
여기서, CLIP 저자들은, Visual Model 에 LLM 개념을 도입해보면 어떨까 생각하게 된다.
LLM의 큰 두 조건은 1. 큰 모델 2. 큰 데이터이다.
이후 논문 내용을 살펴보자.
1. Introduction and Motivating Work
Raw text에서, 직접 학습하는 pre-training method는 지난 몇년동안, NLP 분야에 혁명을 일으켰다. 자동회귀(auto-regressive)와 masked language modeling은 컴퓨팅, 모델 용량, 데이터의 규모를 수배로 확장해 꾸준히 기능을 개선해왔다. text-to-text 의 발전은, input - output 인터페이스의 표준이 되었으며, task-agnostic architecture(task에 구애받지 않는 아키텍처)로 제로샷 transfer가 가능하게 되었으며, 이는 specialized output heads나, dataset specific 커스텀이 필요없어졌다. GPT-3와 같은 flagship 시스템은 이제 많은 작업에서 경쟁력을 가지고 있으며, 데이터셋이 거의 또는 필요없게 되었다.
이러한 결과는, 웹 규모의 텍스트 모음에서, 접근할 수 있는 것이, 고품질 crowd-labele된 NLP 데이터셋보다 우수함을 제시한다. 그럼에도 불구하고, 컴퓨터 비전과 같은 다른 분야에서는 여전히 ImageNet과 같은 군중 라벨링 데이터셋에서 모델을 사전 훈련하는 것이 표준 관행이다. 웹 텍스트에서 직접학습하는 확장가능한 pre-training method는 여전히 연구되고 있는 분야이다.
PoC(Proofs of Concept)는 흥미롭지만, 이미지 표현 학습에 자연어 supervision을 사용하는 경우는 아직 드물다. 이는 일반적인 benchmark에서, 입증된 성능이 다른 접근 방식에 비해 훨씬 낮기 때문일 수 있다. 예를 들어, Li 등 은, ImageNet의 성능을 제로샷 설정에서 11.5%로 측정했다. 이는 고전적인 컴퓨터비전 정확도인 50%와 현재 SOTA모델의 정확도인 88.4%에 훨씬 못미치는 수치이다.
대신에, 범위는 좁지만, 타겟이 명확한 weak supervision을 사용하면, 성능이 향상되었다. Mahajan 등 (2018)은 인스타그램 이미지에서 ImageNet 관련 해시태그를 예측하는 것이 효과적인 사전 훈련 작업임을 보여주었다. 이러한 사전 훈련된 모델을 ImageNet에 맞게 미세조정하면 정확도가 5% 이상 향상되고 당시의 전반적인 기술 수준을 향상시킬 수 있었다. Kolesnikov 외(2019)와 Dosovitskiy 외(2020)는 노이즈가 많은 라벨이 붙은 JFT- 300M 데이터 세트의 클래스를 예측하기 위해 모델을 사전 훈련함으로써 광범위한 transfer benchmark dataset에서 큰 이득을 얻었음을 입증하기도 했다.
이 작업 방식은 제한된 양의 'gold-label'로부터 학습하는 것과 사실상 무제한의 raw-text로부터 학습하는 것 사이의 현재 실용적인 중간 지점을 나타내지만, 이 방법에도 단점은 있었다.
두 연구 모두 각각 클래스를 1000개와 18291개로 제한한다. 자연어는 훨씬 더 광범위한 시각적 개념을 표현할 수 있다. 그러나, 두가지 방식모두 Static sofmax classifier를 사용해, 동적인 출력을 위한 매커니즘이 부족했다. 이는, 유연성이 심각하게 저해되고, 제로샷 기능이 제한된다.
이러한 weak supervised model과 nlp에서 직접 이미지를 표현을 학습하는 최근의 연구사이의 가장 큰 차이점은 "규모"다.
본 연구에서는, natural language supervision 를 통해 대규모로 훈련된 이미지 classifier 의 동작을 제안한다. 인터넷에서 이러한 형태의 공개적으로 사용가능한 대량의 데이터를 활용해서 4억개의 (image-text)쌍의 새로운 데이터세트를 생성하고, 처음부터 훈련된 conVIRT의 단순한 버전인 CLIP이 natural language supervision을 통한 효율적인 학습 방법임을 입증한다. 본 연구에서는, 2배의 달하는 연산규모에 걸친 일련의 8가지 모델을 훈련해, CLIP 의 확정성을 연구하고, transfer 성능이 원활하게 예측 가능한 연산함수라는 것을 입증했다.
이전의 prior task-specific supervised과 비교될 수 있으며, CIP모델이 ImageNEt모델을 능가하는 동시에, 계산적으로 더 효율적임을 보여준다. 또한 제로샷 CLIP 모델이 supervised ImageNet 모델보다 더 강력하다는 사실을 발견했으며, 이러한 결과는 정책 및 윤리적인 측면에서 중요한 의미를 가진다.
+)
기존의 연구를 언급하고 이에 대한 문제점을 시사하며, 본 연구의 장점 및 성과를 서술하고 있다.
2. Approach
2.1 Natural Language Supervision & 2.2 Creating a Sufficiently Large Dataset
CLIP 저자들은 대용량의 데이터셋을 확보하기 위해 인터넷에서 데이터를 모으는 방법을 선택했다. Natural Language Supervision 에서, Supervision 은 Supervised learning 에서 Supervised 와 동일한 뜻으로 "감독/지도"를 의미한다. 따라서 이름 그대로, Natural Language Supervision 은 자연어를 라벨 삼아, 학습시킨다는 것으로 이해하면 된다. 본 연구에서는 이미지와 이미지를 설명하는 문장 4억개쌍을 데이터셋으로 구축한다.
자연어를 통한 학습은 다른 학습 방법에 비해 몇가지 잠재적인 강점이 있다. 이미지 분류를 위한 Crowded-Labeling 에 비해 자연어 supervision 을 확장하기가 훨씬 쉬운데, 정답 클래스를 1/N로 맞추는것이 아니기 때문이다. 또한, 자연어 학습은 대부분의 비지도 또는 자가지도학습 접근 방식에 비해 표현을 단순히 학습하는 것이 아니라 그 표현을 언어와 연결하여 유연한 제로샷 transfer 를 가능하게 한다는 점에서 중요한 이점이 있다.
+) Zero-shot transfer 란?
기계 학습 모델이 훈련 중에 본 적 없는 새로운 작업이나 데이터에 대해 예측할 수 있는 능력을 의미한다. 이러한 방식은 모델이 기존에 학습한 지식을 활용하여 알려지지 않은 상황에 대응할 수 있게 한다. 자연어를 통한 학습은 이러한 제로샷 트랜스퍼 능력을 가능하게 하는 핵심 요소 중 하나다. 자연어는 매우 다양하고 복잡한 정보를 담을 수 있으며, 이를 통해 모델은 다양한 상황과 맥락에서 사용될 수 있는 일반화된 지식을 습득할 수 있다. 이는 모델이 보다 폭넓은 적용 범위를 가지며, 실제 세계의 다양한 태스크에 더 잘 대응할 수 있도록 한다.
2.3 . Creating a Sufficiently Large Dataset
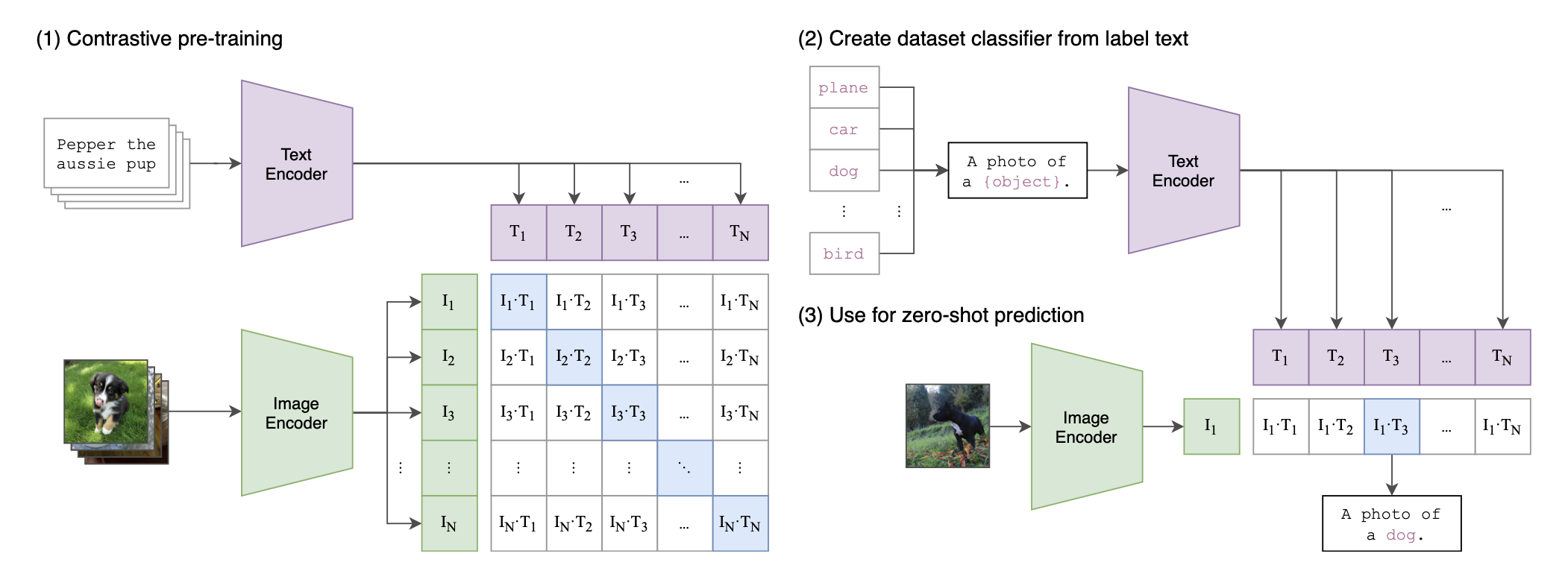
구축된 대규모 데이터셋을 학습하려면 어떻게 해야할까? 기존 ImageNet 처럼, Cross Entrophy Loss 로 학습할 수는 없는데, 왜냐하면 자연어는 Label 과 달리 특정 개수로 구분되지 않기 때문이다. 이미지마다 매칭되어 있는 설명 문장은 모두 다르기 때문이다. 따라서, 이를 Softmax로 구분하는 방식의 학습은 가능하지 않다.
이런 고민 끝에, CLIP 저자들은, Constrastive Learning 을 선택한다. Constrastive 는 "대조"를 의미하며, Constarstive Learning은 매칭되는 데이터 Feature들은 가까워지고, 나머지 Feature들끼리는 멀어지도록 학습하는 방법을 의미한다. 이러한 Constrastive Learning 은 Self Supervised Learning 에서 그 진가를 발휘한다. (Label 정보가 없어도, 어떠한 기준으로 나와 매칭되는지만 설정해주면 학습을 진행할 수 있기 때문이다.) 대표 사례로는 SimCLR이 있는데, 입력이미지에 Augmentation을 적용해 동일한 이미지 버전끼리는 가까워지도록, 다른 이미지 버전과는 멀어지도록 학습했다. 그럼에도, Label 정보 없이도, Label 정보로 학습한 모델에 버금가는 성능을 보여주었다.
위 그림 왼쪽은, CLIP의 Constrastive Learning 을 설명한 그림으로, 파란색으로 칠해져 있는 부분이 Positive Pair를 의미한다. 나머지는 Negative Pair를 의미한다. 데이터셋은 이미지와 이 이미지에 매칭되는 자연어로 구성되어 있으며, 이미지는 Image Encoder로, 자연어는 Text Encoder 로 Feature를 추출한다. T는 텍스트를 의미하고, I는 이미지를 의미하며, N은 배치 개수를 의미한다.
총 N개의 Image Feature가 있고, 마찬가지로, N개의 Text Feature가 추출되며, N X N 조합이 나오는것을 알 수 있다. Constrastive Learning 은 나와 매칭되는 조합은 가까워지도록, 그외의 조합은 멀어지도록 학습하는 방법이다. 여기서, 가깝다는 의미는 두 Feature의 Cosine Similiarity가 커지는 방향을 의미한다. 두개의 Feature가 공간상에서 가까운 각도에 위치할수록 Cosine Similarity는 큰 값을 갖기 때문이다. 반대로 나머지 쌍과는 멀어지도록 모델을 학습한다. 여기서 모델은 Image Encoder와 Text Encoder를 의미한다.
2.4. Choosing and Scaling a Model
이미지 인코더를 위해 두가지 아키텍처를 고려하는데, 첫번째는 ResNet 이다. 조금 더 표현 추출 능력을 강화하기 위해 마지막 Global Average Pooling 부분을 설명해준다. 여기에 Attention 모듈을 추가한 Attention Pooling 으로 적용한다. 두번째는, Vit(Vision Transformer)를 사용한다. 아주 미세한 변화만 주어 사용하는데, 트랜스포머 앞에 결합된 위치임베딩에 추가 layer normalization 을 추가했다. 이렇게 5가지 종류의 ResNet 과 3가지 종류의 ViT를 사용해 실험을 진행한다.
텍스트 인코더는 트랜스포머 모델을 사용하며, 약간의 수정을 가했다.
3. Experiments
3.1 Zero-shot transfer
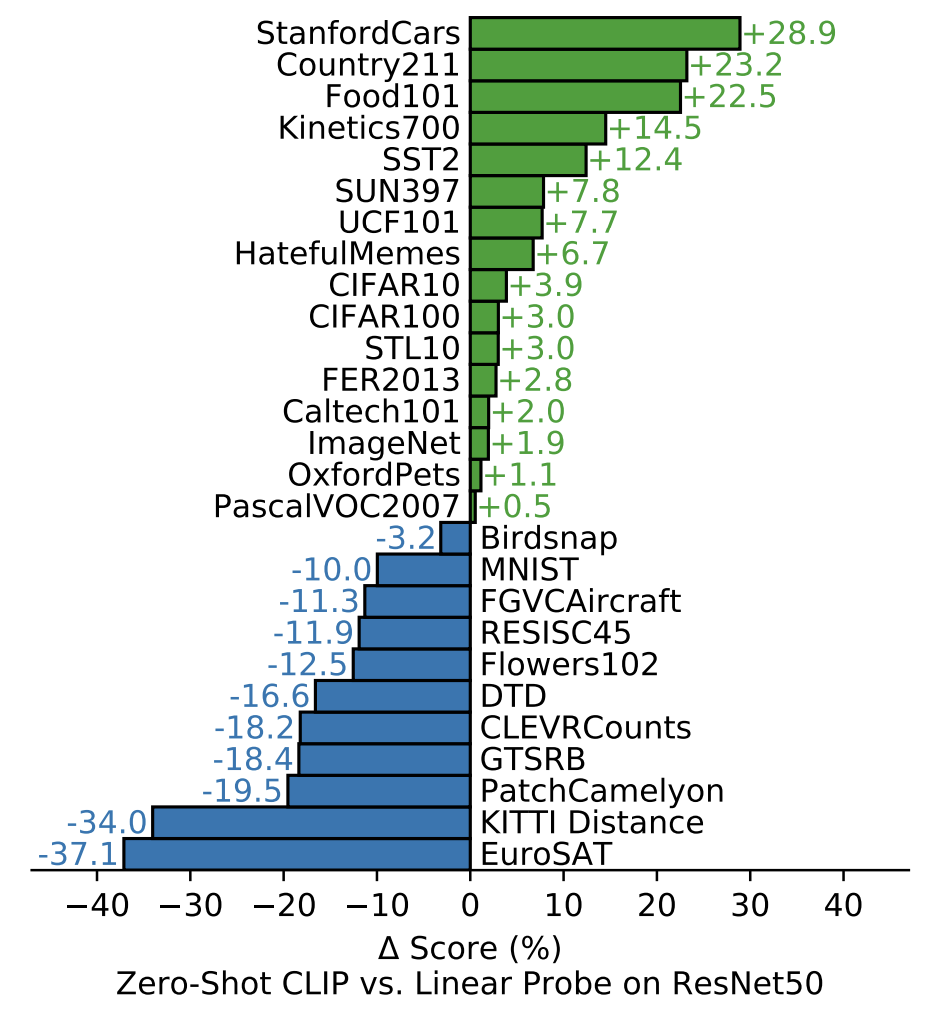
Zero-shot Transfer 실험에서는, zero-shot prediction 방식과, Linear Probing 방식의 성능 비교를 통해, CLIP이 얼마나 좋은 표현을 학습했는지 보여준다.
+) Linear Probing 이란?
Linear probing은 머신 러닝과 특히 자기 지도 학습(self-supervised learning) 분야에서 사용되는 개념이다. 이 방법은 학습된 특성을 평가하는 간단하면서도 효과적인 방식으로, 사전 훈련된 모델의 성능을 검증하는 데 사용된다. 자기 지도 학습에서는 라벨이 없는 데이터를 사용해 모델을 사전 훈련하고, 이 모델이 추출한 특성(feature)의 유용성을 평가하기 위해 선형 분류기(linear classifier)를 적용한다. 여기서 'probing'이란, 사전 훈련된 모델이 학습한 표현(representation)의 질을 탐사하는 과정을 의미한다.
-> Linear Probe란 학습이 완료된 Encoder를 가져와 Supervised Learning으로 Classifier만 재학습해주는 방법이다. 만약 Encoder가 좋은 표현을 많이 학습했다면 단순히 Classifier만 재조정 해주어도 높은 성능이 나올 것이라는 전제가 깔려있는 방법이다.
결과를 보면, fine-grained classification 데이터셋에서는 성능이 좋지 않고, 일반적인 표현학습으로만 풀수 있는 데이터에서는 좋은 성능을 내고 있음을 볼 수 있다. 이러한 결과는 매우 고무적이라고 할 수 있는데, 왜냐하면 모든 데이터셋에서 좋은 결과를 낸 것은 아니지만 Label 데이터를 전혀 사용하지 않고도 Label 정보를 사용하여 학습한 동일한 모델보다 더 좋은 성능을 보여주고 있기 때문이다.
( 위성 이미지 분류(EuroSAT 및 RESISC45), 림프절 종양 감 지(PatchCamelyon), 합성 장면에서 물체 수 세기 (CLEVRCounts), 독일 교통 표지판 인식(GTSRB), 가장 가까운 차량과의 거리 인식(KITTI Distance) 등 자율 주행 관련 작업 등 여러 특수화되고 복잡하거나 추상적인 작업 에서 제로 샷 CLIP이 상당히 취약하다는 것을 확인할 수 있다. 이러한 결과는 더 복잡한 작업에서 제로 샷 CLIP의 성능이 좋지 않다는 것을 보여준다. )
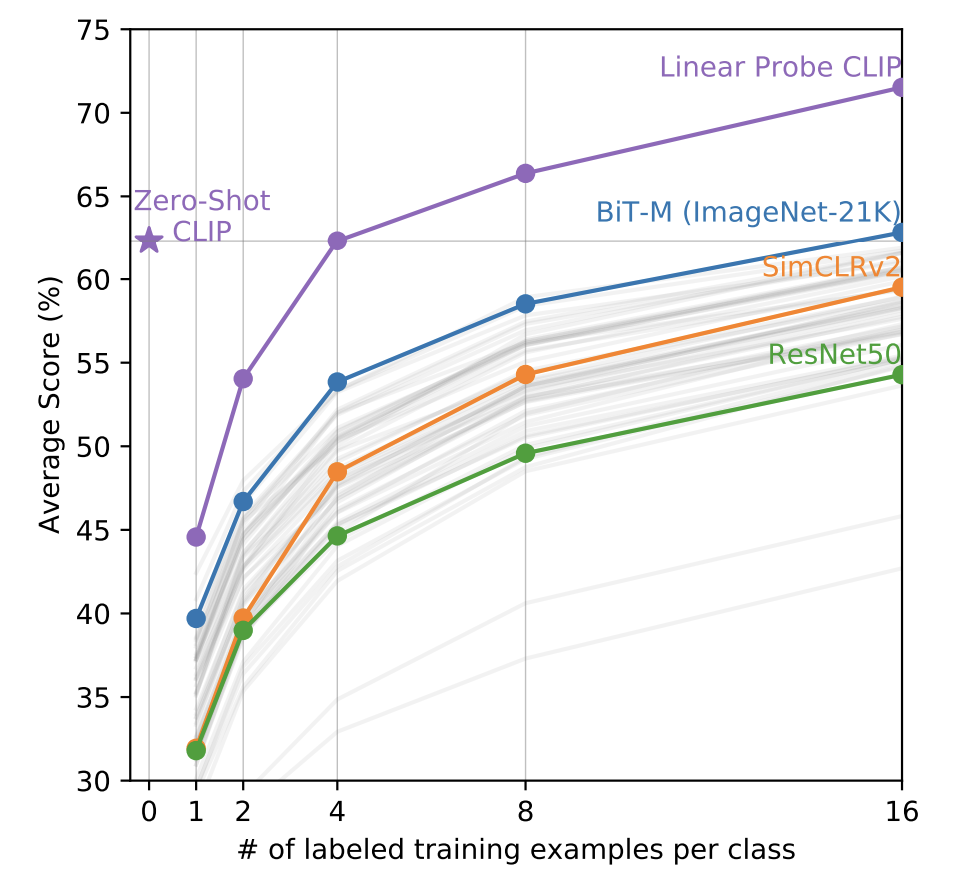
다음 실험은 CLIP과 다른 모델들의 Linear Probing 성능을 비교한 그래프다. x축은 Linear Probing에 사용한 클래스당 데이터 개수를 의미한다. 사전 학습이 완료된 상태에서 몇개의 대표 데이터만을 사용하여 Classifier를 학습했을때 누가 더 성능이 좋은지를 비교한것인데, CLIP 모델이 모든 면에서 다른 모델들보다 Linear Probing 실험에서 좋은 성능을 보인다는 것을 알 수 있다. 기존의 SimCLR, BiT 등 좋은 표현을 학습한다고 알려진 다른 방법들보다 좋은 표현을 학습한다는 점이 검증된 것이다.
또 주목해야 할 부분은 CLIP의 Zero Shot 성능입니다. CLIP의 Zero Shot 성능은 클래스당 4개의 데이터를 학습한 CLIP 모델과 비슷한 수준이고, 다른 모델들은 더욱 많은 데이터셋을 학습해야 낼 수 있는 수준의 성능이다. 이를 통해 CLIP의 Zero Shot 성능이 상대적으로 얼마나 좋은지를 알 수 있다.
'인공지능 논문 리뷰' 카테고리의 다른 글
| [논문정리] Convolution Neural Networks for Sentence Classification (0) | 2023.11.11 |
|---|---|
| [논문 정리] CharCNN 알아보기 - Character-level Convolutional Networks for Text Classification (0) | 2023.08.09 |

