
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- mnist
- 유데미
- 42서울
- 플러터
- 앱개발
- Flutter
- 크롤러
- pytorch
- Computer Vision
- 딥러닝
- 자연어처리
- Regression
- 피플
- map
- CV
- RNN
- filtering
- 머신러닝
- 크롤링
- 파이썬
- 지정헌혈
- 모델
- 인공지능
- AI
- 42경산
- 선형대수학
- 선형회귀
- 회귀
- 코딩애플
- 데이터분석
- Today
- Total
David의 개발 이야기!
[논문정리] Convolution Neural Networks for Sentence Classification 본문
[논문정리] Convolution Neural Networks for Sentence Classification
david.kim2028 2023. 11. 11. 23:27https://arxiv.org/abs/1408.5882
Convolutional Neural Networks for Sentence Classification
We report on a series of experiments with convolutional neural networks (CNN) trained on top of pre-trained word vectors for sentence-level classification tasks. We show that a simple CNN with little hyperparameter tuning and static vectors achieves excell
arxiv.org
원본 논문은 여기서 볼 수 있다!
전체내용을 번역하는 것이 아닌, 핵심 내용을 의역했습니다 :)
Abstract
우리는 문장 수준 분류 작업을 위해 사전 훈련된 단어 벡터 위에 훈련된 컨볼루션 신경망(CNN)을 사용한 일련의 실험에 대해 보고한다. 우리는 간단한 CNN이 조금의 하이퍼파라미터 튜닝과 정적 벡터를 사용하여 여러 벤치마크에서 우수한 결과를 달성한다는 것을 보여준다. 특정 작업에 맞게 벡터를 미세 조정함으로써 성능이 더욱 향상된다. 또한, 과제별 벡터와 정적 벡터를 모두 사용할 수 있도록 아키텍처에 간단한 수정을 제안한다. 여기서 논의된 CNN 모델들은 감정 분석 및 질문 분류를 포함한 7개의 작업 중 4개에서 최신 기술을 개선한다.
1. Introduction
CNN 모델은, 비전분야를 위해 고안되었으나, 자연어처리분야에서도 효과적임을 보여주었다. 본 논문에서는, Unsupervised Neural Language model 에서 얻은 워드 벡터 위에 하나의 레어를 갖는 간단한 CNN 모델을 학습한다. 처음에는 단어벡터를 고정하고, 모델의 다른 매개변수를 학습한다. 하이퍼파라미터의 tunning이 거의 없음에도, 여러 benchmark에서, 우수한 결과를 달성하여, 사전 훈련된 벡터가, 다양한 분류작업에 사용될 수 있는 "보편적(universal)" 추출기라는 것을 의미한다. 특정 작업에 맞는 벡터를 미세조정하여, 더 큰 개선을 이룰 수 있었다. 또, 사전훈련된 벡터와 과제별 벡터를 모두 사용할 수 있도록 아키텍처를 수정하는 방법도 제시한다.
2. Model

$ x_i \in \mathbb{R}^k $는 문장에서 i번째 단어에 해당하는 k차원의 단어 벡터를 나타낸다. 길이가 n인 문장은 다음과 같이 표현될 수 있다:
$$ x_{1:n} = x_1 \oplus x_2 \oplus \ldots \oplus x_n $$
일반적으로, $ x_{i:i+j} $는 i번째 단어부터 (i+j)번째 단어까지 연결한 것을 의미한다. 하나의 합성곱 연산은 필터 $ w \in \mathbb{R}^{h \times k} $를 포함하며, 이는 h개 단어의 윈도우에 적용되어 새로운 특징을 생성한다.
예를 들어, $ x_{i:i+h-1} $의 윈도우에서 생성된 특징 $ c_i $는 다음과 같이 표현될 수 있다:
$$ c_i = f(w \cdot x_{i:i+h-1} + b) $$
여기서 $ b \in \mathbb{R} $은 편향항이고, $ f $는 tanh와 같은 비선형 함수이다. 이 필터는 문장의 가능한 모든 윈도우 { $ x_{1:h}, x_{2:h+1}, \ldots, x_{n-h+1:n} $ }에 적용되며, 다음과 같은 feature map을 생성한다. 이 때 $ c \in \mathbb{R}^{n-h+1} $이다:
$$ c = [c_1, c_2, \ldots, c_{n-h+1}] $$
이후 시간-최대 풀링(max-over-time pooling) 연산을 특징 맵에 적용하여 가장 큰 값 $ \hat{c} = \max\{c\} $을 해당 필터에 상응하는 특징으로 설정한다. 이 풀링 방법은 자연스럽게 가변적인 문장 길이를 처리한다.
지금까지 하나의 필터에서 하나의 특징을 추출하는 과정을 설명했다. 이 모델은 여러 필터를 사용해 여러 특징을 얻는다. 이러한 특징들은 그림의 끝에서 두 번쨰 레이어를 형성하고, 레이블에 대한 확률 분포가 출력 되도록 fully connected softmax layer로 전달된다.
In one of the model variants, we experiment with having two ‘channels’ of word vectors—one that is kept static throughout training and one that is fine-tuned via backpropagation (section 3.2).2 In the multichannel architecture, illustrated in fig- ure 1, each filter is applied to both channels and the results are added to calculate ci in equation (2). The model is otherwise equivalent to the sin- gle channel architecture.
모델 변형 중 하나에서, 우리는 두 가지 '채널'의 단어 벡터를 사용하는 것을 실험한다—하나는 훈련 내내 고정되고, 다른 하나는 역전파를 통해 미세 조정된다. 다채널 아키텍처에서는, 그림 1에 나타난 바와 같이, 각 필터가 두 채널에 모두 적용되고, 그 결과들이 합산되어 식 (2)에서의 $c_i$를 계산한다. 이 모델은 그 외에는 단일 채널 아키텍처와 동일하다.
또한 본 논문에서는, 모델의 변형 중 하나에서 단어 벡터를 2개의 채널로 갖는 실험을 진행했다 - 하나는 학습 동안 단어 벡터를 고정해놓는 것이고, 하나는 역전파를 통해 파인 튜닝 되도록 한 것이다.

2.1 Regularization
Regularization을 위해, 끝에서 두번째 레이어(penultimate layer)에서 Drop-out을 l2-norm 과 함께 사용한다. Dropout 은 co-adaptation 을 방지한다.
Co-adaptation, 동조화
: 특정 뉴런의 가중치나 바이어스가 큰 값을 갖게 되면, 그 특정 뉴런의 영향이 커지면서 다른 뉴런들의 학습 속도가 느려지거나 학습이 제대로 진행되지 못하는 경우.
즉, 끝에서 두 번째 레이어 $ z = [\hat{c}_1, \hat{c}_2, \ldots, \hat{c}_m] $이 주어졌을 때 ($m$은 필터의 개수),
$ y = w \cdot z + b $
을 사용하는 대신에,
$ y = w \cdot (z \circ r) + b $
을 사용한다. 여기서 $ \circ $는 원소별 곱셈을 나타내는 연산자이고, $ r \in \mathbb{R}^m $는 확률 $p$를 가지는 베르누이 확률 변수의 마스킹 벡터이다. 마스킹이 안된 유닛만 사용해 그래디언트가 역전파된다. 테스트 시, 학습된 가중치는 $p$에 의해 조정된다 $ \hat{w} = pw $.
추가적으로 가중치 벡터의 $ \ell_2 $-norm을 제한하기 위해, 경사 하강 단계(gradient descent step) 후에 $ ||w||_2 > s $일 경우 $ ||w||_2 = s $가 되도록 가중치를 rescaling한다.
3. Datasets and Experimental Setup
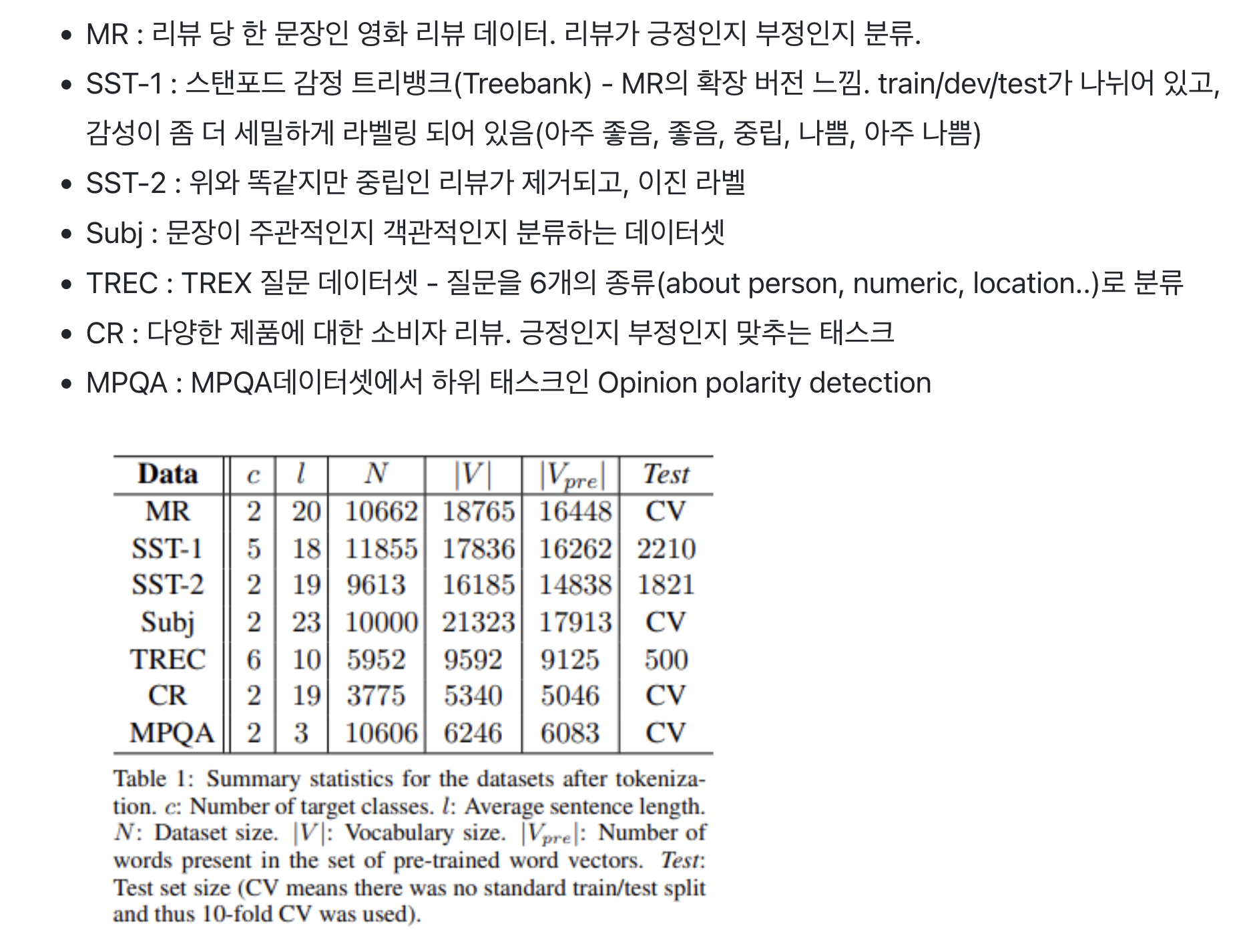
3.1 Hyperparameters and Training
모든 데이터에 대해 사용한 것
- Relu
- filter windows(h) of 3,4,5 with 100 feature maps
- dropout rate(p) of 0.5
- constraint(s) of 3
- mini-batch size of 50
이 설정값들은 SST-2 dev set에 grid search를 사용해 찾음
early stopping 외에 dataset-specific한 튜닝은 없었음.
standard dev set가 없는 데이터셋에 대해선 training data의 10%를 무작위로 선택해 dev set으로 활용.
학습은 Adadelta update rule을 기반으로 무작위로 섞인 mini-batch에 대해 SGD를 통해 진행됨.
3.2 Pre-trained Word Vectors
unsupervised neural language model에서 얻은 워드 벡터로 초기화. 여기선 word2vec 벡터를 사용함. 벡터는 300 차원이고, CBOW방법으로 학습됨. 사전 학습된 단어 집합에 없는 단어는 랜덤하게 초기화.
3.3 Model Variations
모델을 여러 가지 버전으로 실험!
- CNN-rand : 모든 단어를 랜덤하게 초기화, 학습하면서 단어 벡터도 같이 학습.
- CNN-static : word2vec으로 사전 학습된 단어 벡터 사용. 학습 동안 모든 단어는 변동 X, 모델의 파라미터만 학습
(사전 학습된 단어 집합에 없어서 랜덤하게 초기화한 단어 포함) - CNN-non-static: word2vec으로 사전 학습된 단어 벡터 사용. 사전 학습된 단어가 각 태스크에 맞춰 파인 튜닝 됨.
- CNN-multichannel : 워드 벡터 집합이 2개인 모델. 각 벡터 집합은 "channel"로 처리되고, 각 필터는 두 채널 모두에 적용되지만 역전파는 채널 중 하나만 사용 . 그래서 이 모델은 한 채널은 파인 튜닝이 됐지만, 한 채널은 static을 유지. 두 채널 모두 word2vec으로 초기화 됨.
위의 변화와 다른 임의 요소의 효과를 분리하기 위해 CV-fold 할당, 단어 집합에 없는 단어 초기화, CNN 파라미터 초기화와 같은 임의성을 가지는 요소들을 균일하기 유지.
4. Results and Discussion

- baseline 모델인 CNN-rand는 성능이 좋지 않았음
- 사전학습된 벡터를 사용한 모델은, 성능이 좋았음
- static vectors를 쓴 CNN-static 은, 다른 복잡한 딥러닝 모델 또는 parse tree가 필요한 모델보다 remarkably well 동작했다.
=> 이는, 사전학습된 벡터들은, good, "universal" feature extractors이고, 다른 데이터셋에도 활용가능함을 보여준다.
- CNN-non-static 결과를 보면, 각 task 에 맞춰, fine-tuning 하는 것이 대체로 좋은 성능을 보인다.
4.1 Multichannel VS Single Channel Models
본 논문 저자들은, 다채널 아키텍처가, 학습된 벡터들이 원래의 값에서 멀어지지 않게 함으로써, overfitting을 방지해, 단일 채널 모델보다 더 좋은 성능(특히, 작은 데이터셋에서)을 낼 것이라 생각했다. 그러나 결과는 비슷했다.
4.2 Static vs Non-Static Representations
CNN-static 모델은, 단어 벡터 학습을 하지 않지만, CNN-non-static 모델은 단어 학습까지 진행한다. 따라서, 두 모델의 단어 벡터를 살펴보면, 얼마나 fine-tuned 되었는지 확인 가능하다.

단일 채널 비정적(non-static) 모델과 마찬가지로, 다중 채널 모델도 비정적 채널을 특정 작업에 더 적합하게 미세 조정할 수 있다. 예를 들어, word2vec에서 'good'은 'bad'와 가장 유사하다고 가정된다. 이는 두 단어가 문법적으로 거의 동등하기 때문이다. 하지만 SST-2 데이터셋에서 미세 조정된 비정적 채널의 벡터에서는 이러한 상황이 더 이상 적용되지 않는다(표 3 참조). 마찬가지로, 감정을 표현하는 데 있어 'good'은 'great'보다 'nice'에 더 가깝다고 볼 수 있으며, 이는 학습된 벡터에 실제로 반영된다. 미리 학습된 벡터 세트에 포함되지 않은 (임의로 초기화된) 토큰들의 경우, 미세 조정을 통해 더 의미 있는 표현을 학습할 수 있다: 네트워크는 느낌표가 강한 표현과 관련되어 있고 쉼표가 접속적인 역할을 한다는 것을 학습한다
4.3 Further Observation
- Kalchbrenner et al. (2014)는 본 논문의 단일 채널 모델과 본질적으로 같은 CNN으로 더 안좋은 결과를 기록했다. 예를 들어, 그들의 max-TDNN(Time Delay Neural Network)은 SST-1에 대해 37.4%였지만, 우리 모델은 45%였다. 아마 이 차이는 우리 CNN이 더 높은 수용력(capacity- 여러 필터 너비와 특징맵)를 갖기 때문인 것으로 보인다.
- Dropout이 좋은 정규화 수단임이 증명되었다. Dropout은 지속지속적으로 2%-4%정도의 성능을 더했다.
- word2vec에 없는 단어를 랜덤으로 초기화 할 때, 랜덤으로 초기화 된 벡터가 사전 학습된 벡터와 동일한 분산을 갖도록 a를 선택해 에서 각 차원을 샘플링하여 약간의 개선을 얻었다!
- 다른 사전 학습된 단어 벡터보다 word2vec이 훨씬 좋았다.
- Adadelta는 Adagrad와 유사한 결과를 주지만 epochs이 더 적게 듦.
5. Conclusion
word2vec위에 간단한 CNN을 사용한 본 논문의 모델은, 약간의 하이퍼파라미터 튜닝과, 1개의 layer를 가진 CNN으로도 훌륭한 성능을 보였다. Un-supervised pre-training of word vectors가 NLP에서 중요한 ingredient가 될 수 있음을 볼 수 있다.

