
David의 개발 이야기!
TF-IDF 에 대해 알아보자 - Term Frequency-Inverse Document Frequency 본문
TF-IDF 를 사용하면, 기존의 DTM 보다 더 많은 것을 고려해 문서들을 비교할 수 있다. 많은 경우에서, TF-IDF 가 DTM 보다 좋은 성능을 낸다.
2023.08.09 - [인공지능공부] - DTM 에 대해 알아보자 - Document-Term Matrix
DTM 에 대해 알아보자 - Document-Term Matrix
1. DTM 이란? 문서 단어행렬(DTM)은 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것임 문서1 : 먹고 싶은 사과 문서2 : 먹고 싶은 바나나 문서3 : 길고 노란 바나나 바나나 문서4 : 저
david-kim2028.tistory.com
1. TF-IDF(단어 빈도-역문서 빈도)
TF-IDF 는 단어의 빈도와 역문서빈도(문서의 빈도에 특정 식을 취함)을 사용해 DTM 내 각 단어들마다 중요한 정도에 따라 가중치를 주는 방법이다. 우선 DTM 을 만들고, TF-IDF 가중치를 부여한다.
TF-IDF는 주로 문서의 유사도를 구하거나, 검색시 검색결과의 중요도를 정하거나, 문서 내에서 특정 단어의 중요도를 구하는 작업에 쓰일 수 있다.
TF-IDF 를 식으로 나타내면,
문서 : d
단어 : t
빈도 함수 : f
문서 총 개수 : n
(1) f(d,t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수.
==> DTM에서 각 단어들이 가진 값과 동일(DTM 개념을 모른다면, 위 포스팅 참조)
(2) df(t) : 특정 단어 t가 등장한 문서의 수
(3) idf(d, t) : df(t)에 반비례하는 수.

log를 씌어주는 이유는, 문서의 수가 커질수록, IDF 값이 기하급수적으로 커지는 문제 때문!
log를 안씌우면 아래 표처럼 된다.
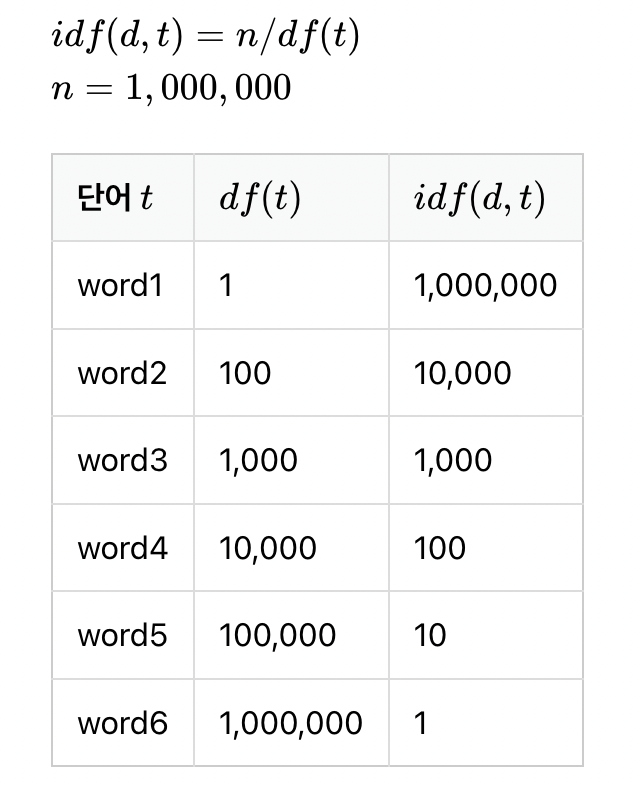
log를 씌우면, 아래 표처럼 된다! (확연히 조정되는 걸 볼 수 있다.)

TF-IDF 는 모든 문서에서 자주 등장하는 단어는 중요도가 낮고, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단한다. TF-IDF 값이 낮으면 중요도가 낮은것이고, 크면, 중요도가 높다고 판단한다. 즉, the, a 같이 불용어의 경우, TF-IDF 의 값은 다른 단어의 TF-IDF에 비해 낮아지게 된다.
2. TF-IDF 구하기
문서1 : 먹고 싶은 사과
문서2 : 먹고 싶은 바나나
문서3 : 길고 노란 바나나 바나나
문서4 : 저는 과일이 좋아요
이런 문서들이 있다고 하자.
1. DTM 나타내기
DTM 으로 나타내면 아래와 같다.

2. IDF 구하기
TF-IDF 공식대로 계산하면 아래 표와 같다.

3. TF-IDF 구하기
DTM 에서 단어별로 IDF 값을 곱해주면 TF-IDF 값을 얻는다.

'자연어처리' 카테고리의 다른 글
| RNN 에 대해 알아보자 (0) | 2023.08.19 |
|---|---|
| N-gram 언어모델에 대해 알아보자 - N-gram Language Model (0) | 2023.08.09 |
| 자연어처리를 위한 1D CNN 이해하기 - 1D Convolutional Neural Networks (0) | 2023.08.09 |
| DTM 에 대해 알아보자 - Document-Term Matrix (0) | 2023.08.09 |
| Bag of Words(BoW)에 대해 알아보자 (0) | 2023.08.09 |

